Currently there are four models, but more models will be added
This project examines how U.S. economic and financial conditions transmit to South Korea’s economy across markets and the real sector. Because there are many candidate indicators—spanning growth, risk sentiment, interest rates, exchange rates, and trade—careful variable selection is essential before modeling. Goal of this section is to build multivariate models to answer four questions:
how U.S. and Korean equities interact
how the Seoul metropolitan housing market responds to Long end of the term structure
which exogenous factors move the won–dollar exchange rate
which factors drive Korea’s exports to the U.S.
Literature reviews
Before turning to the analysis, a targeted literature review aligns the four questions with the overarching research objective and justifies each modeling choice.
In U.S.–South Korea equity linkages, Kim (2010)1 documents significant spillovers in higher moments (mean, volatility, skewness, kurtosis) between U.S. and Korean equity markets using high-frequency data, indicating that U.S. shocks propagate to Korean returns; more recently, a study in Business and Economic Research shows that changes in the VIX are negatively associated with KOSPI returns, reinforcing a U.S. risk-to-Korea transmission channel. Together, these results support a VAR that treats U.S. equity performance and global risk as upstream drivers of Korean equities, with a discount-rate control: include Δlog(S&P 500), VIX, Δlog(KOSPI), and a U.S. yield spread (10Y–3M or 10Y–2Y) to capture the rate channel affecting both markets.
For the Seoul housing market, Lee (2022)2 uses a Korean time-varying parameter VAR (1991–2022) and finds that the impact of interest-rate shocks on housing prices strengthened markedly after the global financial crisis, implying state-dependent pass-through from rates to valuations. Complementary evidence from Min (2024)3 likewise highlights time-varying impulse responses of Seoul housing to interest rates. These findings motivate a compact VAR comprising the U.S. 10-year Treasury yield, the Korea 10-year government bond yield, and the log of the Seoul housing price index, ordered to trace global-to-local rate pass-through and then housing, while leaving room to test time variation via rolling windows or TVP extensions.
For the KRW/USD exchange rate, Yoon (2019)4 argues that U.S. monetary conditions dominate KRW/USD dynamics given the dollar-centric trading of Korea’s FX market, while Masujima (2018, RIETI)5 adds that exchange-rate drivers rotate across carry (rate differentials), the global dollar factor, and risk sentiment (VIX). These insights support a SARIMAX for Δlog(USD/KRW) with exogenous terms for the U.S.–Korea interest-rate spread (3Y or 10Y), Δlog(Dollar Index, DXY) to capture the global dollar cycle, and a risk proxy (VIX or Δlog(S&P 500))—a structure also consistent with funding-risk episodes highlighted for Korea by the IMF.
Finally, on South Korea’s exports to the United States, a Bank of Korea working paper on dominant currency pricing (Son et al., 2023)6 shows that Korean exports are heavily invoiced in U.S. dollars due to strategic complementarities and real hedging, implying that the dollar level often matters for short-run trade revenues. Pairing this with a U.S. demand proxy captures the real-side pull. Accordingly, model Δlog(Korea’s exports to the United States) with U.S. manufacturing demand (ISM Manufacturing PMI or U.S. industrial production), an exchange-rate term (Δlog(USD/KRW) and/or DXY for invoicing effects), and a risk/financing control (VIX), with seasonal terms for monthly data.
The bilateral exchange rate quoted as won per dollar; it moves up when the USD strengthens or U.S. rates/risk rise and down when KRW demand or relative KR rates strengthen; up-moves mean a weaker KRW and costlier imports/funding while down-moves mean stronger KRW and easier external conditions; it matters because it transmits U.S. financial shifts into Korea’s prices, trade margins, and capital flows.
U.S.–Korea 3-year yield spread
The 3Y U.S. Treasury yield minus the 3Y Korea Treasury Bond yield; it widens when U.S. front-to-belly rates outpace Korea’s and narrows when Korea’s rise or U.S. fall; widening implies policy divergence favoring USD assets and KRW pressure, narrowing implies the opposite; it matters as a near-term compass for FX, flows, and local funding costs.
U.S.–Korea 10-year yield spread
The 10Y U.S. Treasury yield minus the 10Y Korea government bond yield; it moves with relative long-run growth/inflation expectations and term premium; wider spreads signal capital preference for U.S. duration and KRW headwinds, narrower spreads point to relatively easier conditions for Korea; it matters for portfolio allocations, currency valuation, and long-tenor financing.
S&P 500 index
The main U.S. large-capital equity benchmark; it rises with stronger earnings/risk appetite and falls on growth scares or tighter policy; gains signal global risk-on that often supports KOSPI and KRW, while declines flag risk-off and potential outflows from Korea; it matters as the world’s equity bellwether shaping cross-border sentiment.
Dollar Index (DXY)
A broad USD index versus major currencies(JPY,GBP,EUR,CAD,SEK,CHF); it rises with stronger U.S. growth/real yields or heightened risk and falls when global growth broadens or the Fed eases; increases mean tighter global financial conditions and KRW headwinds, decreases mean relief; it matters because it frames Korea’s external competitiveness and dollar funding costs.
South Korea exports to the United States (USD)
The monthly value of Korean goods shipped to the U.S.; it rises with firm U.S. demand/tech upcycles and falls when U.S. activity softens or conditions tighten; increases mean stronger external demand and earnings support for Korea, decreases warn of slower production and profits; it matters as a direct real-economy link between the two countries.
VIX (U.S. equity volatility index)
Implied 30-day volatility from S&P 500 options; it spikes in stress and recedes in calm; higher readings mean risk-off, likely KRW weakness and KOSPI pressure, lower readings mean risk-on support; it matters as a fast, forward-looking gauge of global risk that transmits into Korean assets.
U.S. manufacturing index (ISM Manufacturing PMI)
A diffusion index of U.S. factory activity where 50 marks expansion; it rises with stronger orders/production and falls with slowdowns; higher prints mean firmer U.S. goods demand that often lifts Korean exports, lower prints caution on future orders; it matters as a timely cue for Korea’s trade and industrial cycle.
U.S. yield spread (10Y–3Y curve slope)
The term spread between long and intermediate Treasuries; it steepens on improving growth/term premium and inverts ahead of slowdowns; steepening often signals risk-on and better global momentum, inversion warns of softer demand; it matters because it foreshadows the external environment Korea will face.
KOSPI index
Korea’s main equity benchmark; it rises with global risk appetite, stable/strong KRW, and tech strength, and falls when the dollar tightens conditions or volatility jumps; up-moves mean improving earnings/flows, down-moves mean de-risking and potential outflows; it matters as the market-price readout of Korea’s cyclical exposure to U.S. conditions.
U.S. 10-year Treasury yield
The anchor long-term U.S. risk-free rate; it rises on stronger growth/less-dovish policy or higher term premium and falls on easing or growth fears; higher yields mean tighter global discount rates and KRW/KOSPI headwinds, lower yields mean relief; it matters because it sets the tone for valuation and borrowing costs worldwide.
South Korea 10-year government bond yield
Korea’s benchmark long-term sovereign yield; it rises with domestic inflation/growth or spillovers from higher U.S. yields and falls with easing/disinflation; increases mean tighter local conditions and pricier mortgages/corporate debt, decreases mean looser conditions; it matters for domestic credit, housing, and investment.
Seoul residential property price index
An index of Seoul home prices; it rises with lower mortgage rates/strong incomes and softens when rates rise or credit tightens; up-moves signal wealth effects and consumption support, down-moves flag cooling demand and potential credit restraint; it matters as a slower-moving but powerful transmission channel from global rates to the household economy.
Model explanation
VAR model 1 — Equity co-movements (S&P 500, VIX, U.S. yield spread, KOSPI)
Financial linkages transmit U.S. equity and risk shocks to Korean equities through discount-rate and sentiment channels, with feedback over short horizons. The VAR includes Δlog(S&P 500), VIX, the U.S. yield spread (10Y–3M or 10Y–2Y), and Δlog(KOSPI) as jointly endogenous variables. This set captures the main transmission mechanisms: the yield spread summarizes shifts in discount rates and growth expectations; S&P 500 represents U.S. equity innovations; VIX captures global risk aversion; and KOSPI reflects Korea’s market response. A VAR is justified because these variables interact contemporaneously and with lags; the system enables impulse responses from U.S. rate/equity/risk shocks to KOSPI, and variance decompositions that quantify the U.S. contribution to Korean equity volatility.
VAR model 2 — Rates pass-through and Seoul housing (US10Y, KR10Y, Seoul HPI)
Housing valuations in Seoul are sensitive to financing conditions, and global rate movements typically filter through to domestic long-term yields before affecting prices with lags. The VAR comprises the U.S. 10-year Treasury yield, the Korea 10-year government bond yield, and the log of the Seoul housing price index. This configuration reflects a plausible ordering of influences: global long rates anchor international term structures, domestic long rates transmit the shock into local borrowing costs and mortgage pricing, and housing prices adjust gradually via affordability and discount-rate channels. A VAR is warranted because long rates and housing prices exhibit mutual dynamics and delayed pass-through; the framework traces how a U.S. term-structure shock propagates to Korean yields and then to housing over time, while allowing tests for lag length, stability, and time-variation.
SARIMAX model 1 — USD/KRW determinants
Exchange-rate behavior in Korea is strongly influenced by cross-border interest-rate differentials, global risk sentiment, and the broad dollar cycle, reflecting the market’s integration with U.S. monetary conditions and dollar funding. The model includes the U.S.–Korea 3-year yield spread, the S&P 500, and the Dollar Index (DXY) as exogenous drivers of USD/KRW. The spread captures carry/UIP forces and relative monetary stance; the S&P 500 serves as a high-frequency proxy for global risk-on/off that tends to strengthen or weaken KRW; and DXY isolates the common dollar factor that moves bilateral rates beyond country-specific fundamentals. SARIMAX fits because USD/KRW exhibits strong serial correlation that ARIMA errors can handle, while the exogenous block reflects reasonably weakly exogenous global forces at the chosen frequency.
SARIMAX model 2— South Korea exports to the U.S.
International trade research shows that partner-country demand, currency valuation, and global risk conditions jointly shape export dynamics—especially for economies like Korea that are tightly linked to U.S. manufacturing cycles and invoice a large share of exports in dollars. The model uses U.S. manufacturing activity (e.g., ISM Manufacturing PMI or U.S. industrial production), the KRW/USD spot rate, and the VIX as exogenous regressors for South Korea’s exports to the U.S. This selection is justified by clear channels: the U.S. manufacturing index captures external demand pull; the KRW/USD rate captures pricing and competitiveness as well as dollar-denominated revenue effects; and the VIX proxies global financial conditions that influence trade finance, inventory decisions, and risk-sensitive orders. A SARIMAX structure is appropriate because exports are persistent and seasonal, allowing ARIMA terms to absorb autocorrelation and seasonality while treating the U.S. indicators and VIX as upstream drivers at monthly frequency.
Models
SARIMAX:
South korea exports(vs USA) ~ VIX + US manufacturing Index + KRW/USD spot rate
USD/KRW spot rate ~ us-korea spread rate 3years+ us-korea spread rate 3years+ S&P500 + dollar index
VAR:
equity: s&p500, vix, us_yield_spread,KOSPI index
US treasury yield curve 10 Years, South Korea government bond rate 10Years, Seoul housing index
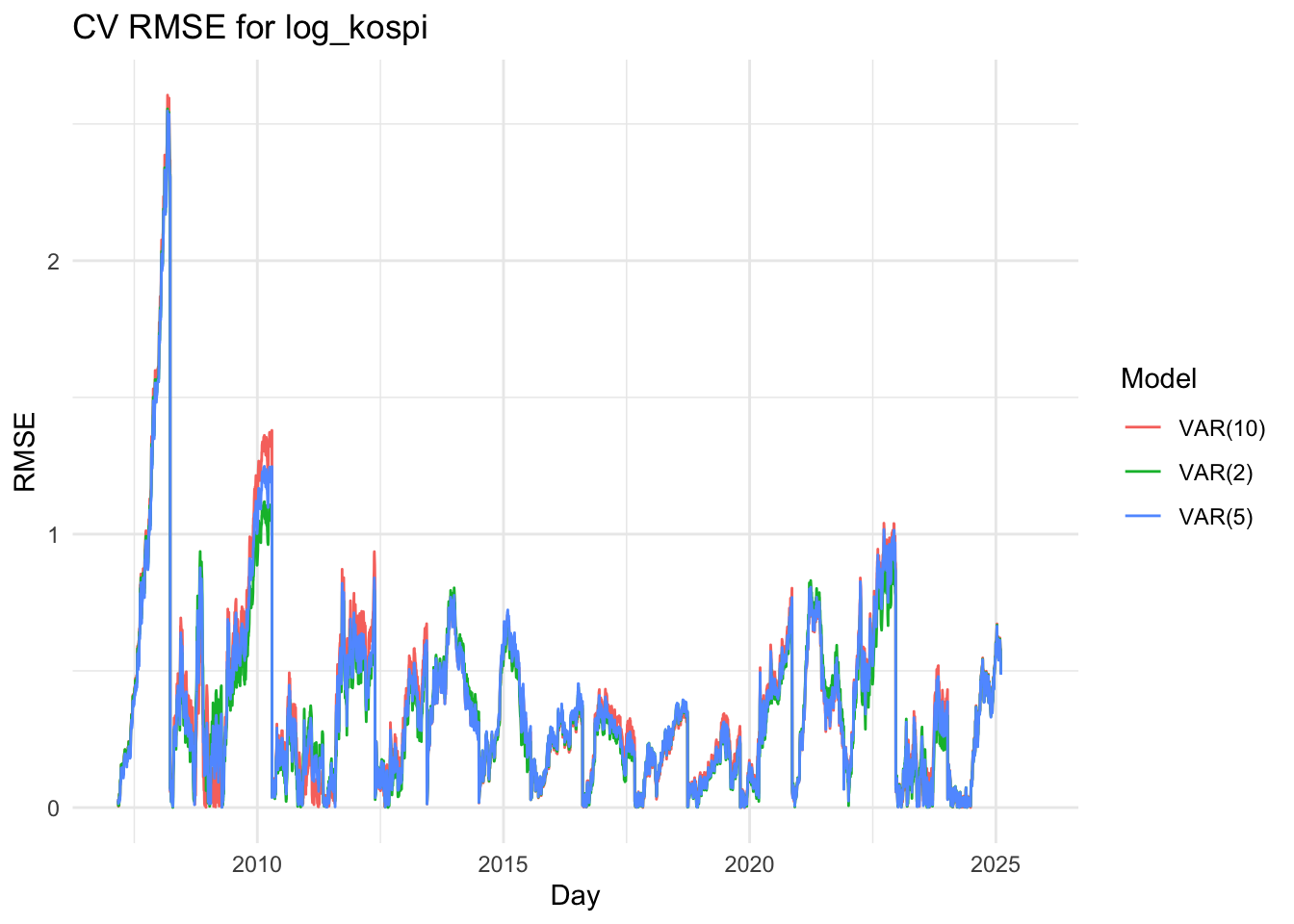
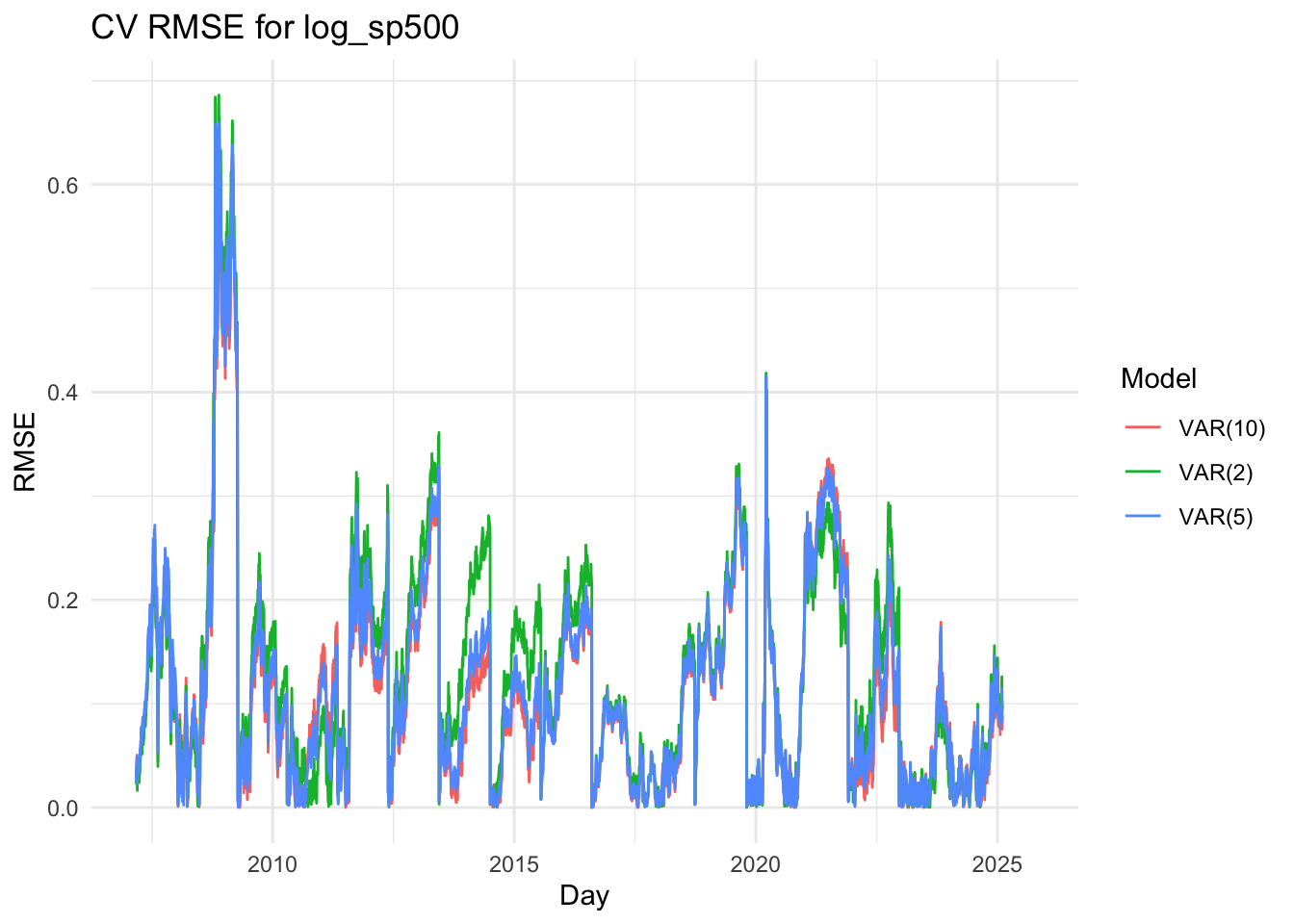
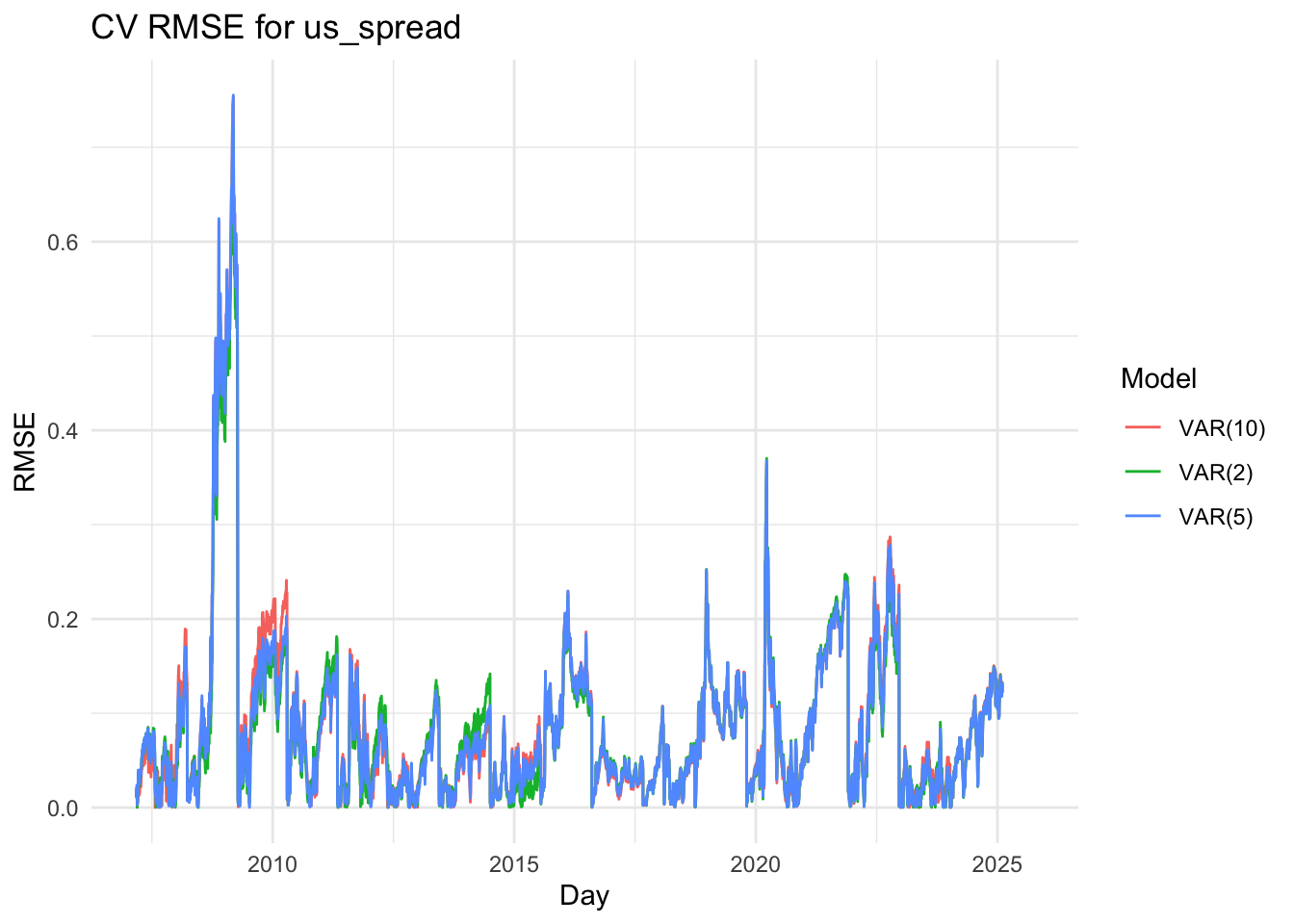
The VAR(2) model captures the short-term dynamics among the variables efficiently. The U.S. spread (us_spread) equation is mainly driven by its own lagged values, while both the Korean and U.S. stock indices (log_kospi and log_sp500) show strong dependence on their own past values and some cross-market effects. Most coefficients are statistically significant, and the model achieves a high R-squared (above 0.999) with low residual correlations, indicating a good fit and stable dynamics (all roots below one).
The VAR(5) model slightly improves the overall fit, as reflected by a marginal increase in log-likelihood and a small reduction in residual variance. Some additional lag terms, especially for the stock market variables, become significant, suggesting that the model captures medium-term interdependencies between the U.S. and Korean markets. However, several higher-order lag coefficients remain insignificant, implying that the added complexity provides limited explanatory gain.
The VAR(10) model, while achieving the highest log-likelihood, shows minimal improvement in explanatory power relative to the VAR(5) model. Many of the higher-order lag terms are statistically insignificant, and the R-squared values remain nearly identical to those of the simpler models. This indicates potential overfitting, as the model includes many parameters without substantial improvement in predictive accuracy.
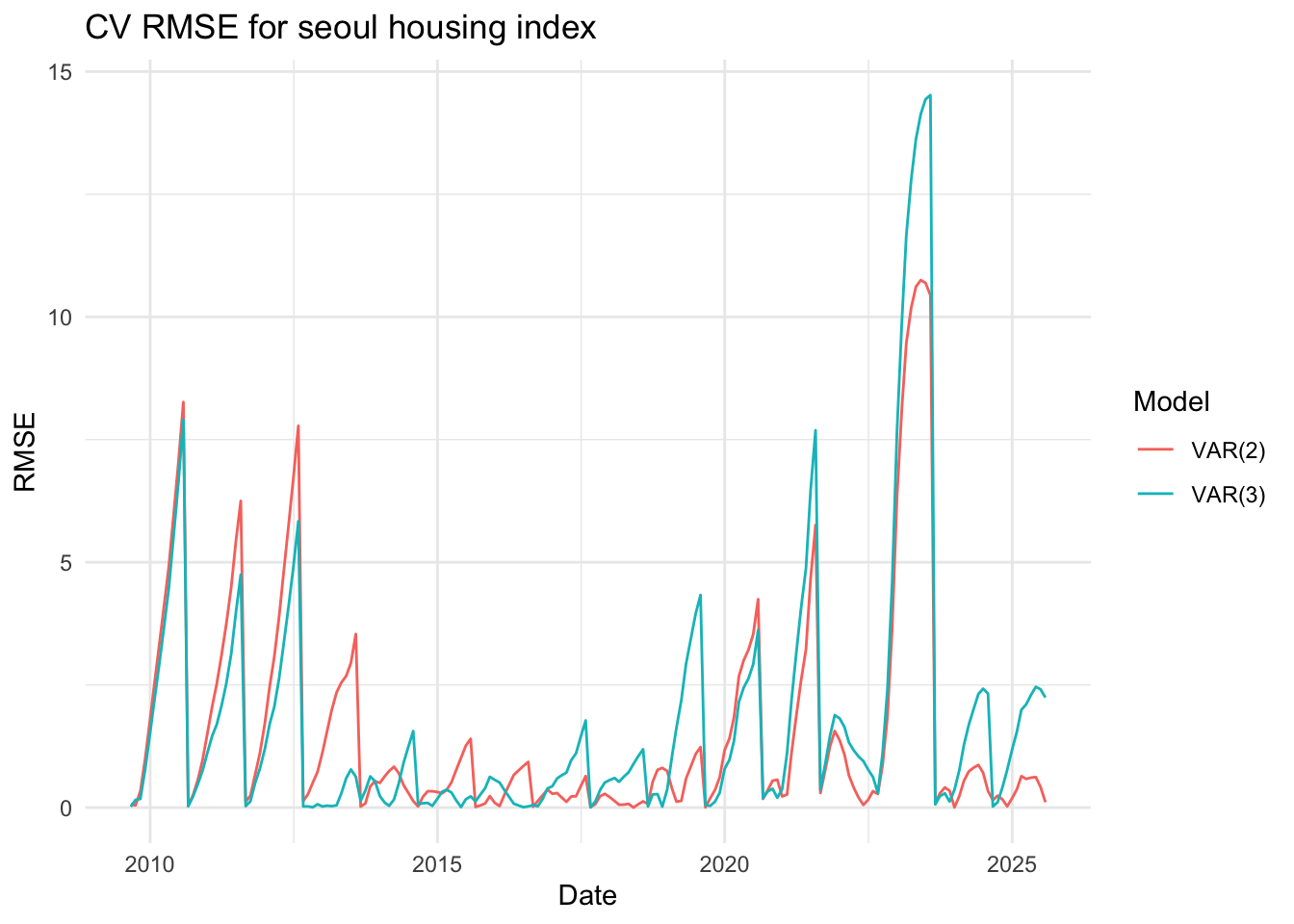
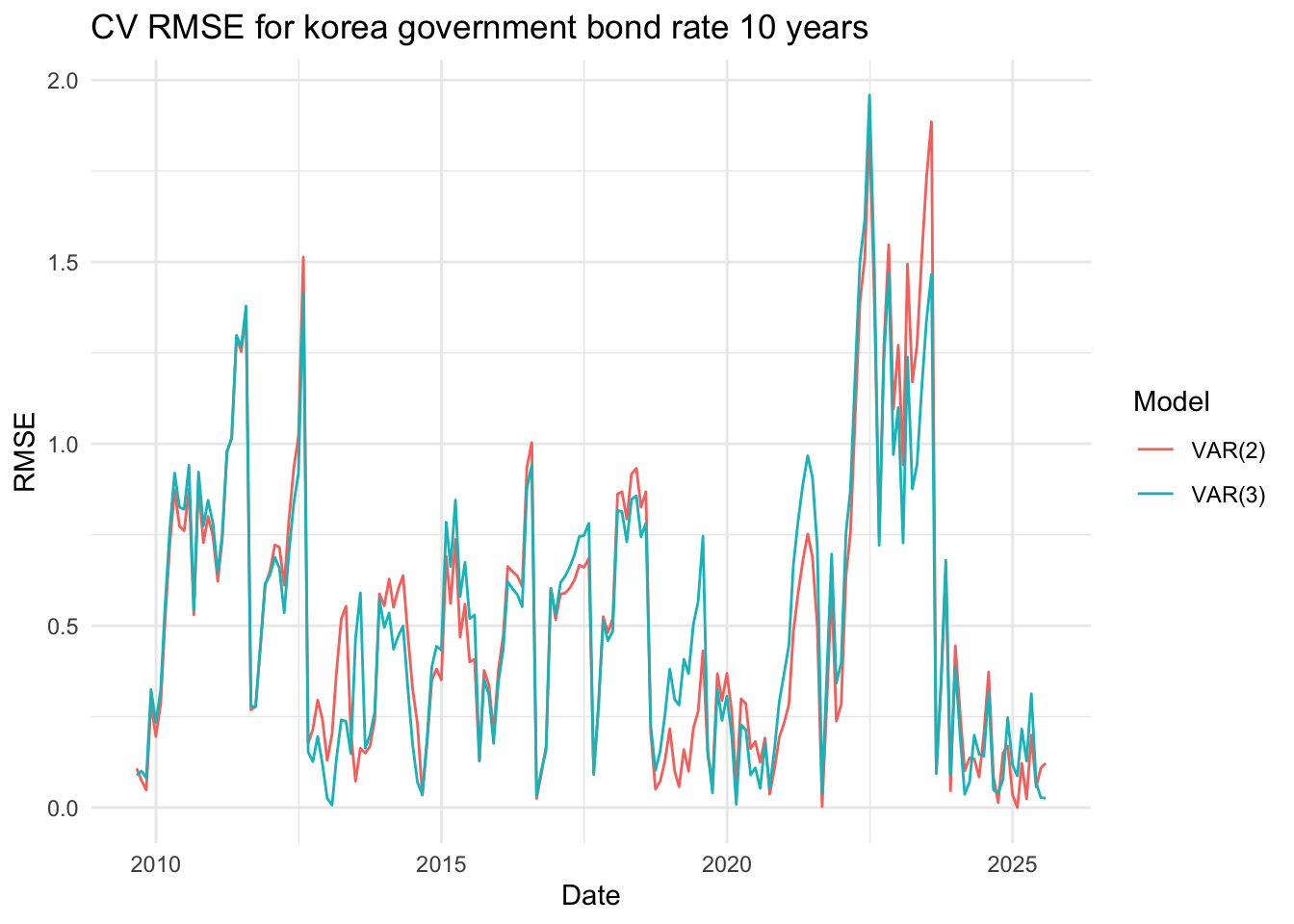
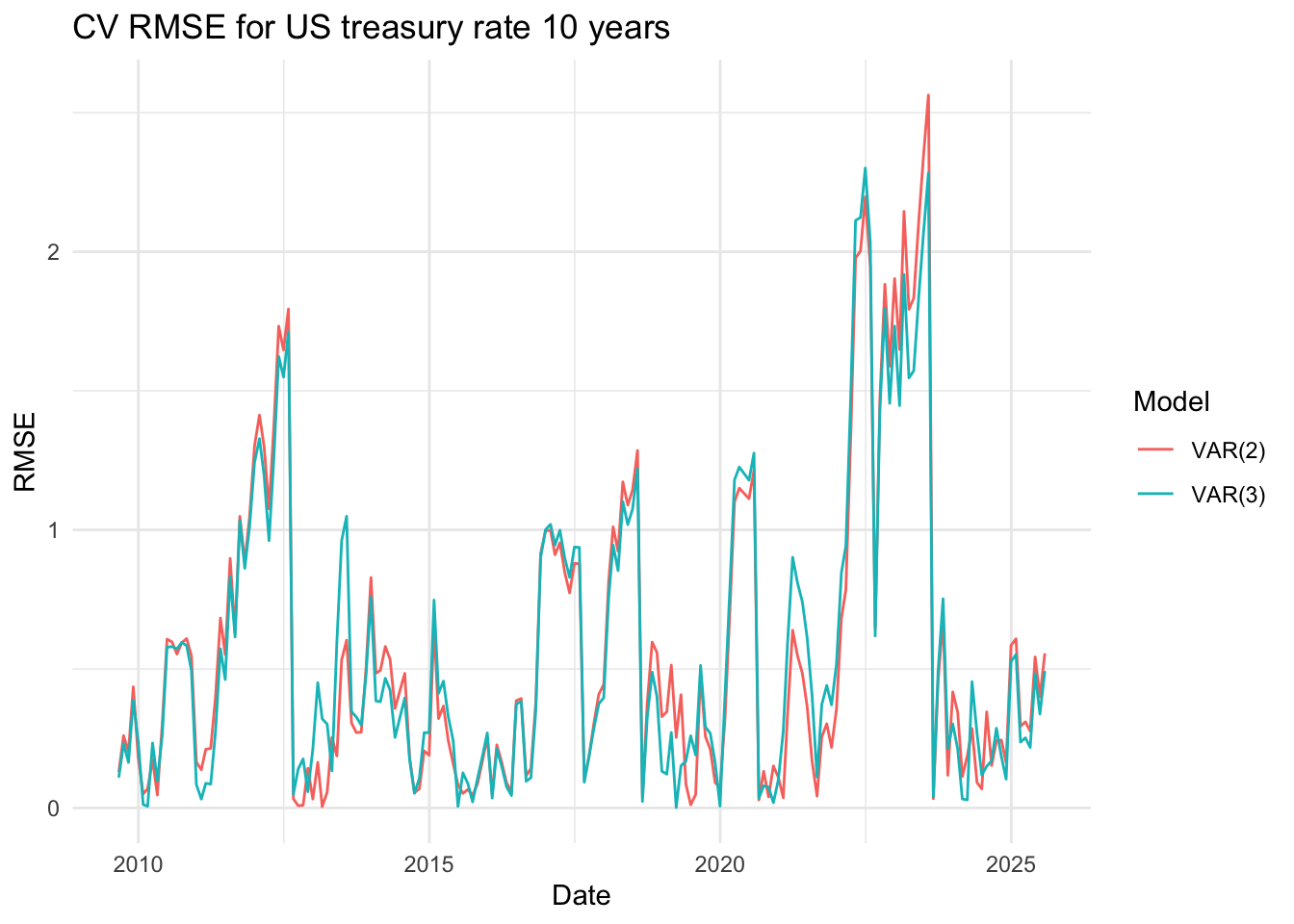
The three line plots above show the RMSE values for three variables, comparing the VAR(2),VAR(5) and var(10) models. Although it’s somewhat difficult to clearly distinguish which model performs better based solely on the plots, the VAR(2) model appears to have slightly lower RMSE values overall. Therefore, I decided to proceed with the VAR(5) model for further analysis.
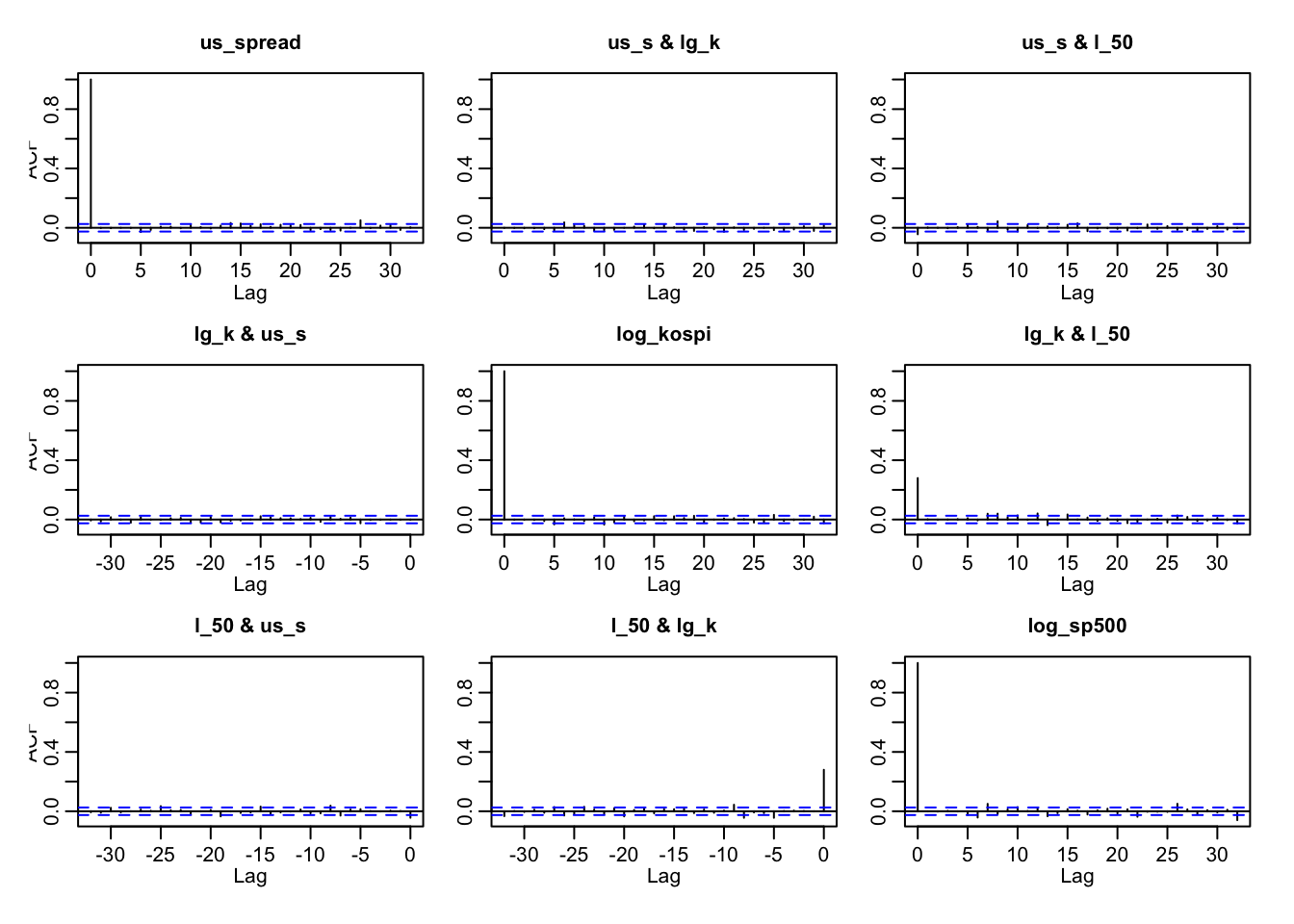
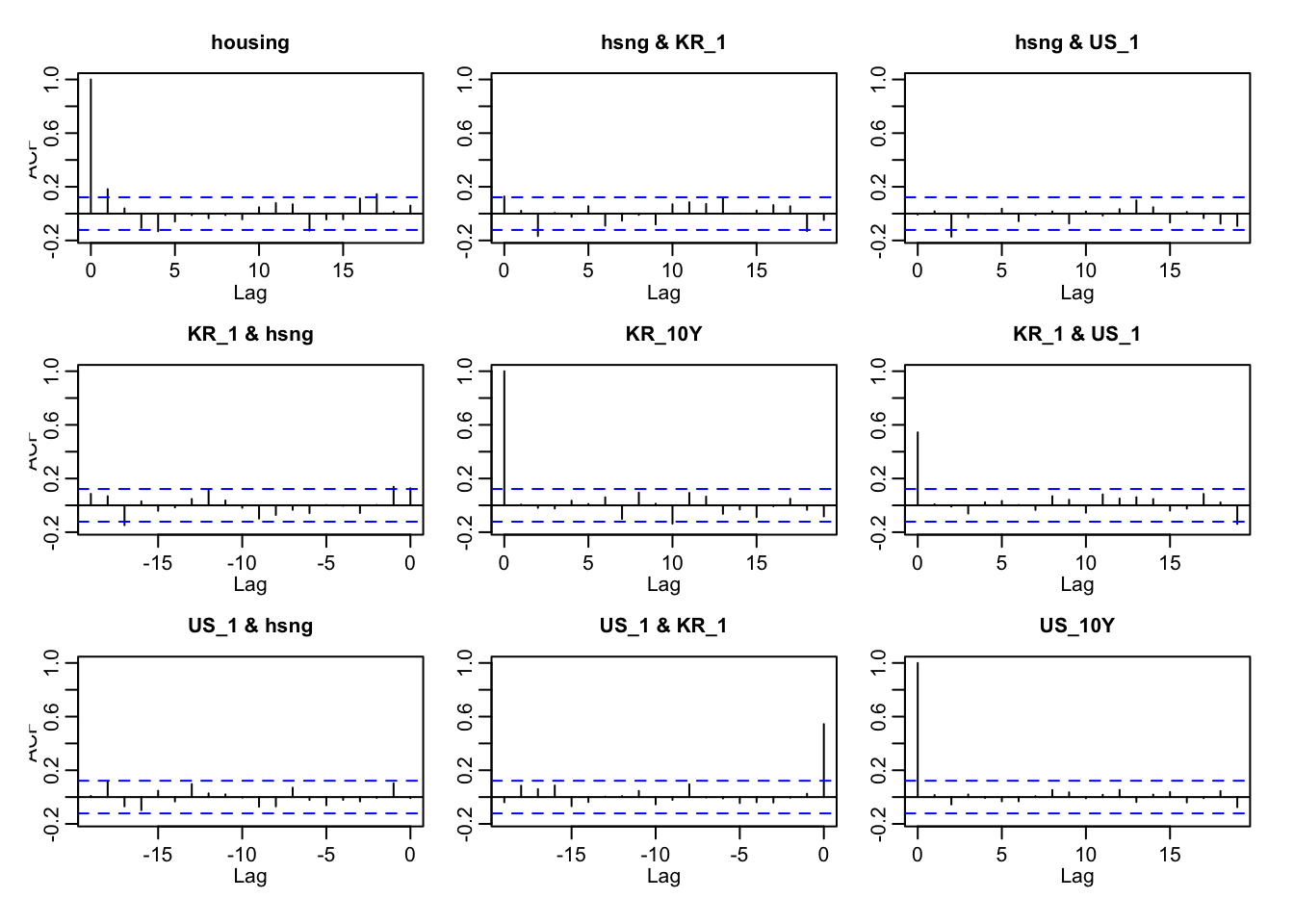
last plot is a acf plot for var(5) model’s residuals. From the plot, the residual autocorrelations are mostly within the 95% confidence bounds , except for a strong spike at lag 0, which simply reflects the correlation of each residual with itself. The absence of significant spikes beyond lag 0 suggests that the VAR(5) specification has successfully removed serial correlation from the system. This implies that the model order (p=5) is sufficient.
Overall, the ACF of the residuals confirms that the VAR(5) model is appropriately specified and that the residuals behave as approximately white noise.
From the forecast plot, the VAR model demonstrates a good fit, accurately capturing the patterns of past data and projecting trends for the next two years. The model forecasts an increase in the U.S. 3-year and 10-year spreads as well as the S&P 500 index, while predicting an opposite movement for the KOSPI index.
This result is both interesting and economically reasonable. As the U.S. yield spreads rise, investors are likely to favor U.S. dollar–denominated assets, leading to a stronger dollar. However, this appreciation of the USD tends to weaken the Korean won (KRW), which in turn exerts downward pressure on the KOSPI index.
US treasury yield curve 10 Years, South Korea government bond rate 10Years, seoul housing index
In the VAR(2) model, the housing variable is primarily driven by its own past values, with highly significant coefficients for its first and second lags (positive and negative, respectively), implying mean-reverting dynamics. Korean and U.S. long-term interest rates (KR_10Y and US_10Y) have only weak short-run effects on housing, as most of their coefficients are statistically insignificant. The KR_10Y equation shows strong persistence—its own first and second lags are significant and positive—and a significant influence from the U.S. 10-year yield, suggesting cross-country linkages in bond markets. The U.S. yield (US_10Y) equation confirms high persistence as well, with its first lag strongly significant, while the trend term is also positive and significant, indicating a gradual upward drift. Residual correlations show moderate co-movement between KR_10Y and US_10Y (ρ ≈ 0.54) but only weak links between interest rates and housing.
The VAR(3) model slightly improves the log-likelihood (from 45.63 to 61.07) and marginally lowers residual variances, suggesting a better fit. Additional lag terms introduce some new dynamics: the third lag of housing becomes positive and significant, implying cyclical adjustment, while the second lag of KR_10Y is now significant and negative, and the third lag positive, showing alternating effects on housing. In the KR_10Y equation, housing’s first, second, and third lags all become significant, reinforcing feedback from the housing market to Korean yields. The U.S. yield equation remains dominated by its own autoregressive terms, with limited cross-effects, though housing’s influence is now slightly stronger. Overall, the VAR(3) captures more complex intertemporal relationships and richer lag structures, but the incremental explanatory gain over VAR(2) is small, and most new coefficients are marginally significant.
Code
df2$Date <-as.Date(df2$Date)series_names <-c("housing", "KR_10Y", "US_10Y")ts_obj <-ts(df2[, series_names],start =c(year(df2$Date[1]), month(df2$Date[1])),frequency =12)n <-nrow(df2)k<-69h <-12n_k <- n - knum_blocks <-floor(n_k / h)rmse2 <-matrix(NA_real_, n_k, 3) rmse3 <-matrix(NA_real_, n_k, 3) st <-tsp(ts_obj)[1] + (k -1) /12for (i in1:num_blocks) { xtrain <-window(ts_obj, end = st + i -1) xtest <-window(ts_obj,start = st + (i -1) +1/12,end = st + i)if (NROW(xtest) != h) next fit2 <- vars::VAR(xtrain, p =2, type ="both") fcast2 <-predict(fit2, n.ahead = h) ff2 <-cbind( fcast2$fcst$housing[, 1], fcast2$fcst$KR_10Y [, 1], fcast2$fcst$US_10Y [, 1] ) year <- st + (i -1) +1/12 ff2 <-ts(ff2, start =c(year, 1), frequency =12) a <-12* i -11 b <-12* i rmse2[a:b, ] <-sqrt((ff2 - xtest)^2) fit3 <- vars::VAR(xtrain, p =3, type ="both") fcast3 <-predict(fit3, n.ahead = h) ff3 <-cbind( fcast3$fcst$housing[, 1], fcast3$fcst$KR_10Y [, 1], fcast3$fcst$US_10Y [, 1] ) ff3 <-ts(ff3, start =c(year, 1), frequency =12) rmse3[a:b, ] <-sqrt((ff3 - xtest)^2)}colnames(rmse2) <- series_namescolnames(rmse3) <- series_namesmonth_index <-1:n_kdates1 <-as.Date(df2$Date[(k +1):n])if (length(dates1) < n_k) { dates1 <-c(dates1, rep(as.Date(NA), n_k -length(dates1)))} elseif (length(dates1) > n_k) { dates1 <- dates1[1:n_k]}rmse2_df <-data.frame(month_index, dates1, rmse2, row.names =NULL)names(rmse2_df) <-c("Month","Date", series_names)rmse2_df$Model <-"VAR(2)"rmse3_df <-data.frame(month_index, dates1, rmse3, row.names =NULL)names(rmse3_df) <-c("Month","Date", series_names)rmse3_df$Model <-"VAR(3)"rmse_combined <-rbind(rmse2_df, rmse3_df)
Code
ggplot(data = rmse_combined, aes(x = Date, y = housing, color = Model)) +geom_line() +labs(title ="CV RMSE for seoul housing index",x ="Date",y ="RMSE",color ="Model" ) +theme_minimal()
Code
ggplot(data = rmse_combined, aes(x = Date, y = KR_10Y, color = Model)) +geom_line() +labs(title ="CV RMSE for korea government bond rate 10 years",x ="Date",y ="RMSE",color ="Model" ) +theme_minimal()
Code
ggplot(data = rmse_combined, aes(x = Date, y = US_10Y, color = Model)) +geom_line() +labs(title ="CV RMSE for US treasury rate 10 years",x ="Date",y ="RMSE",color ="Model" ) +theme_minimal()
The three line plots above show the RMSE values for three variables, comparing the VAR(2) and VAR(3) models. Although it’s somewhat difficult to clearly distinguish which model performs better based solely on the plots, the VAR(2) model appears to have slightly lower RMSE values overall. Therefore, I decided to proceed with the VAR(2) model for further analysis.
last plot is a acf plot for var(2) model’s residuals. From the plot, the residual autocorrelations are mostly within the 95% confidence bounds , except for a strong spike at lag 0, which simply reflects the correlation of each residual with itself. The absence of significant spikes beyond lag 0 suggests that the VAR(2) specification has successfully removed serial correlation from the system. This implies that the model order (p=2) is sufficient.
Overall, the ACF of the residuals confirms that the VAR(2) model is appropriately specified and that the residuals behave as approximately white noise.
The forecast suggests that yield curve rates are expected to decrease gradually over time, signaling a potential easing of monetary conditions. In contrast, the Seoul Residential Property Price Index is projected to increase, moving in the opposite direction. A decline in long-term yields often signals market expectations for lower policy rates in the future. Such expectations tend to stimulate the housing market, as lower interest rates reduce borrowing costs, making it cheaper to finance real estate purchases. Consequently, easier monetary conditions can lead to stronger demand and higher residential property prices.
SARIMAX model: USD/KRW spot rate ~ us-korea spread rate 3years+ us-korea spread rate 10years+ S&P500+ dollar index
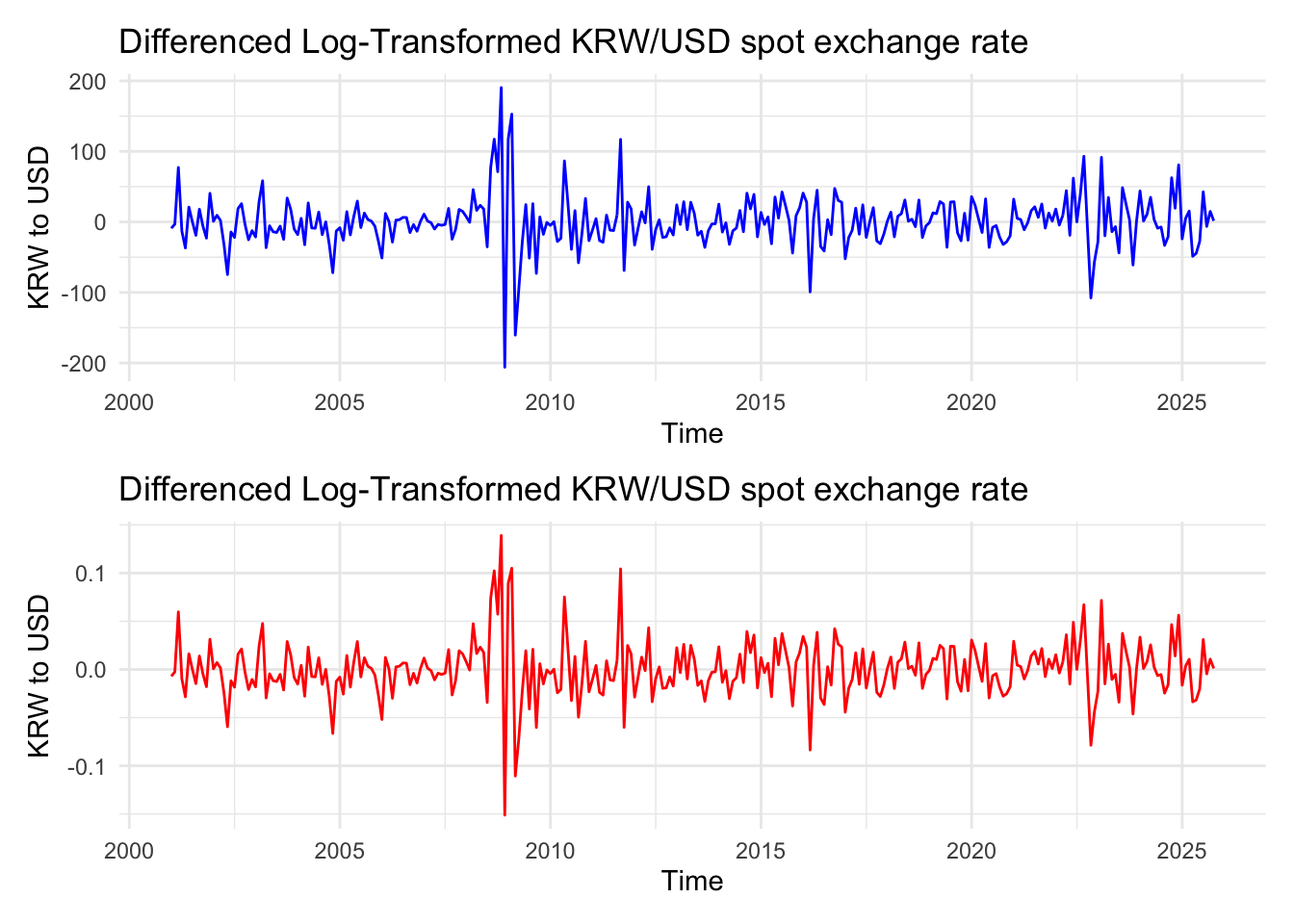
In EDA and univariate section, taking log for S&P500 index and USD index was better, so it will continue to use log transformation. however, here, FX rate needs to be checked
Code
diff_krw <-diff(ts_krw)diff_log_krw <-diff(ts_log_krw)p1 <-ggplot() +geom_line(aes(x =time(diff_krw), y = diff_krw), color ="blue") +labs(title ="Differenced Log-Transformed KRW/USD spot exchange rate",x ="Time",y ="KRW to USD") +theme_minimal()p2 <-ggplot() +geom_line(aes(x =time(diff_log_krw), y = diff_log_krw), color ="red") +labs(title ="Differenced Log-Transformed KRW/USD spot exchange rate",x ="Time",y ="KRW to USD") +theme_minimal()p1 / p2
from the plot, log transformation don’t give dramatical change, so for this model, original value for KRW/USD spot exchange rate will be used.
Series: y1
Regression with ARIMA(0,0,5)(1,0,1)[12] errors
Coefficients:
ma1 ma2 ma3 ma4 ma5 sar1 sma1 intercept
1.0185 0.9192 0.8077 0.5132 0.2915 0.0587 0.1304 -3430.4807
s.e. 0.0866 0.1075 0.0744 0.0742 0.0843 0.3159 0.3023 354.6735
US_KR_3Y US_KR_10Y log_usd_index log_sp500_close
-32.8100 2.1624 962.0504 28.3890
s.e. 12.9267 13.0775 72.4748 23.0226
sigma^2 = 1189: log likelihood = -1477.74
AIC=2981.48 AICc=2982.76 BIC=3029.59
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set 0.2861407 33.77607 24.36759 -0.08942715 2.051096 0.3106065
ACF1
Training set 0.09697159
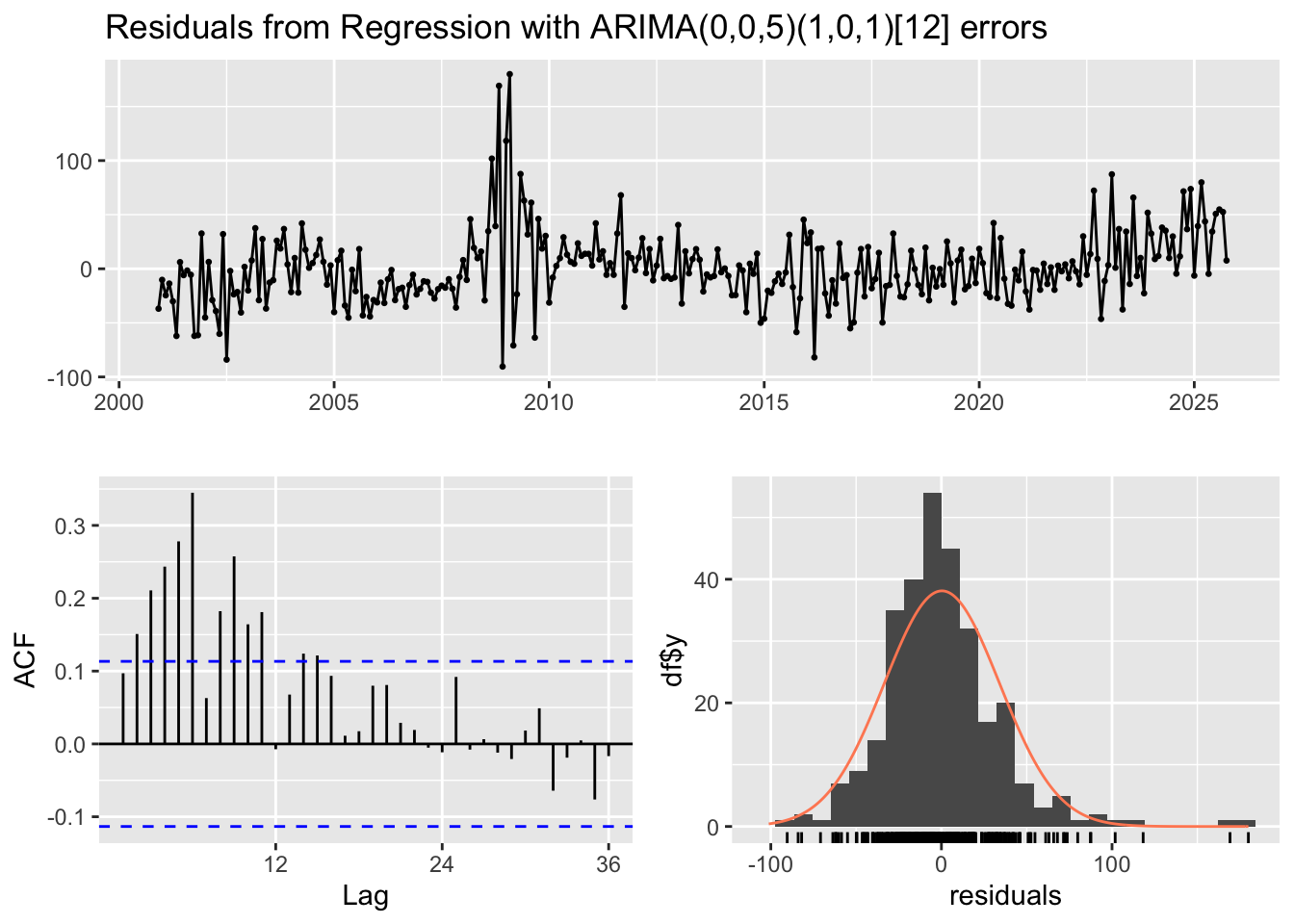
Code
checkresiduals(fit_auto1)
Ljung-Box test
data: Residuals from Regression with ARIMA(0,0,5)(1,0,1)[12] errors
Q* = 170.72, df = 17, p-value < 2.2e-16
Model df: 7. Total lags used: 24
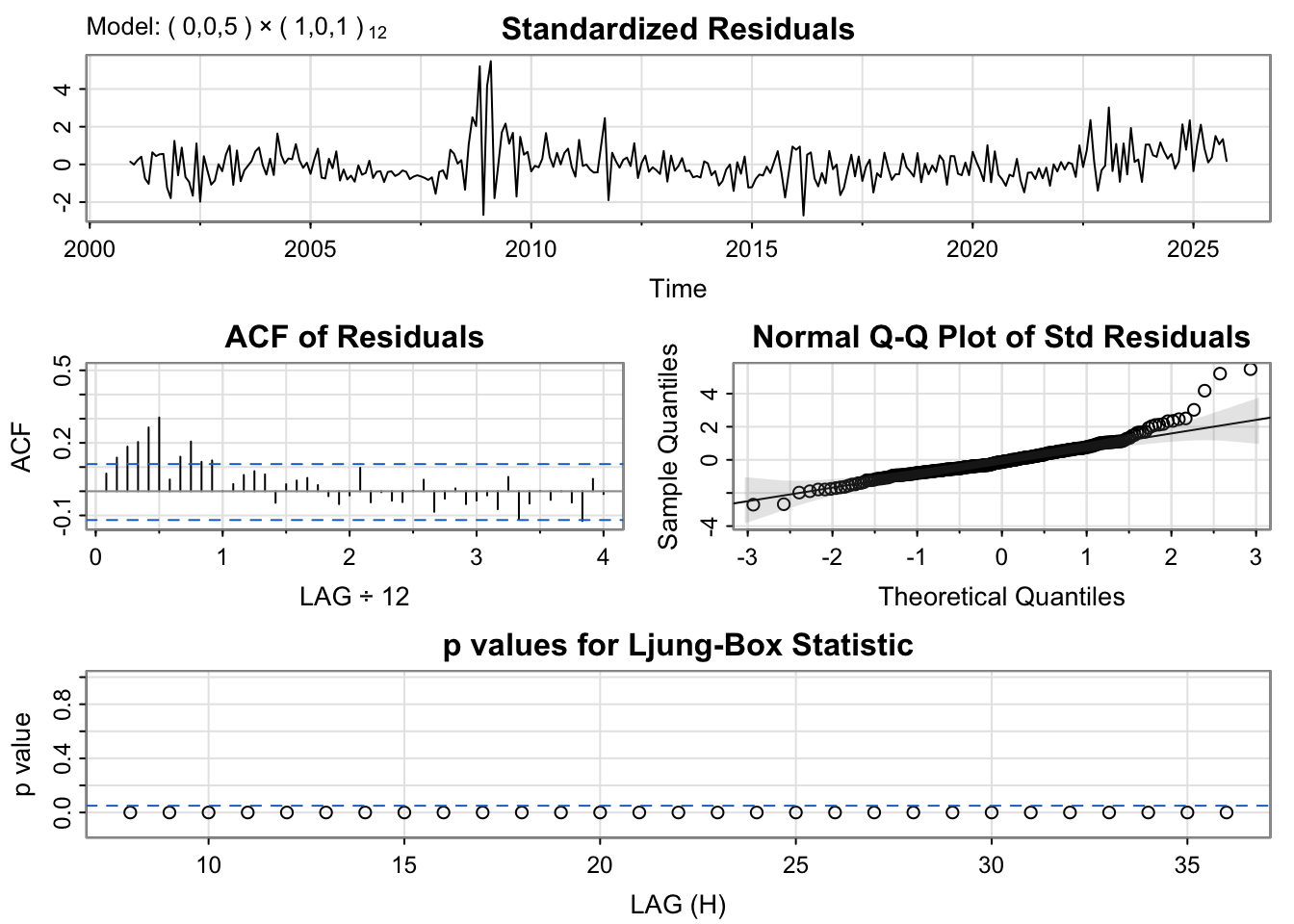
The auto.arima model exhibits noticeable autocorrelation, with a significant spike in the ACF before lag 12, suggesting the presence of remaining short-term dependence that the model has not fully captured. Additionally, the residual series displays visible fluctuations, including a pronounced period of volatility between 2008 and 2010, indicating potential structural changes or outliers during that time. These patterns imply that the model may be under-differenced or missing key components to adequately capture the temporal dynamics and seasonal structure of the data.
Call:
lm(formula = krw ~ US_KR_3Y + US_KR_10Y + log_sp500_close + log_usd_index,
data = df3)
Residuals:
Min 1Q Median 3Q Max
-143.28 -65.07 -13.86 45.71 448.57
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3085.90 245.24 -12.583 < 2e-16 ***
US_KR_3Y -64.56 10.48 -6.160 2.38e-09 ***
US_KR_10Y 32.00 13.99 2.288 0.0229 *
log_sp500_close 92.78 14.00 6.626 1.65e-10 ***
log_usd_index 774.29 51.50 15.036 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 85.87 on 294 degrees of freedom
Multiple R-squared: 0.533, Adjusted R-squared: 0.5266
F-statistic: 83.87 on 4 and 294 DF, p-value: < 2.2e-16
Code
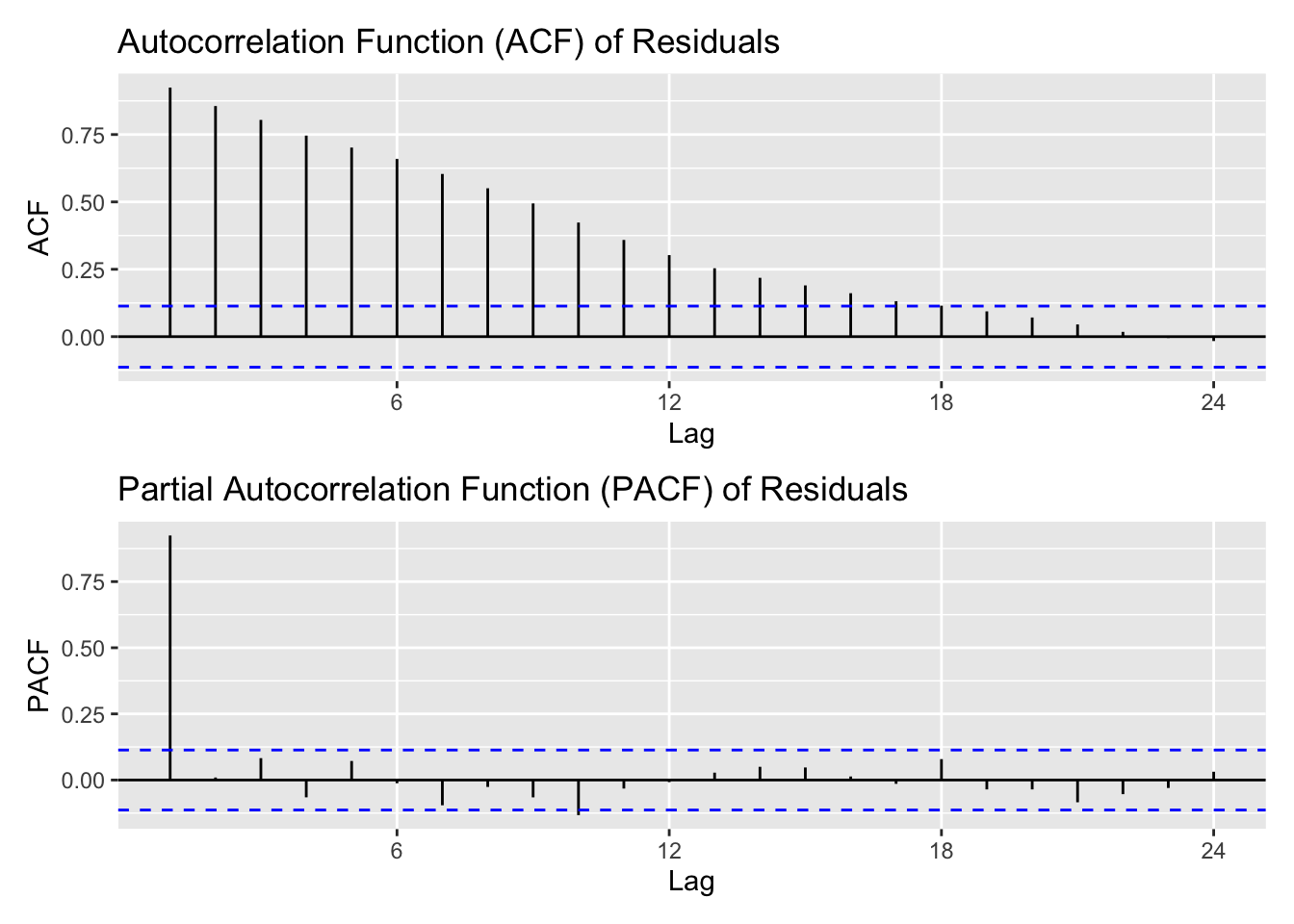
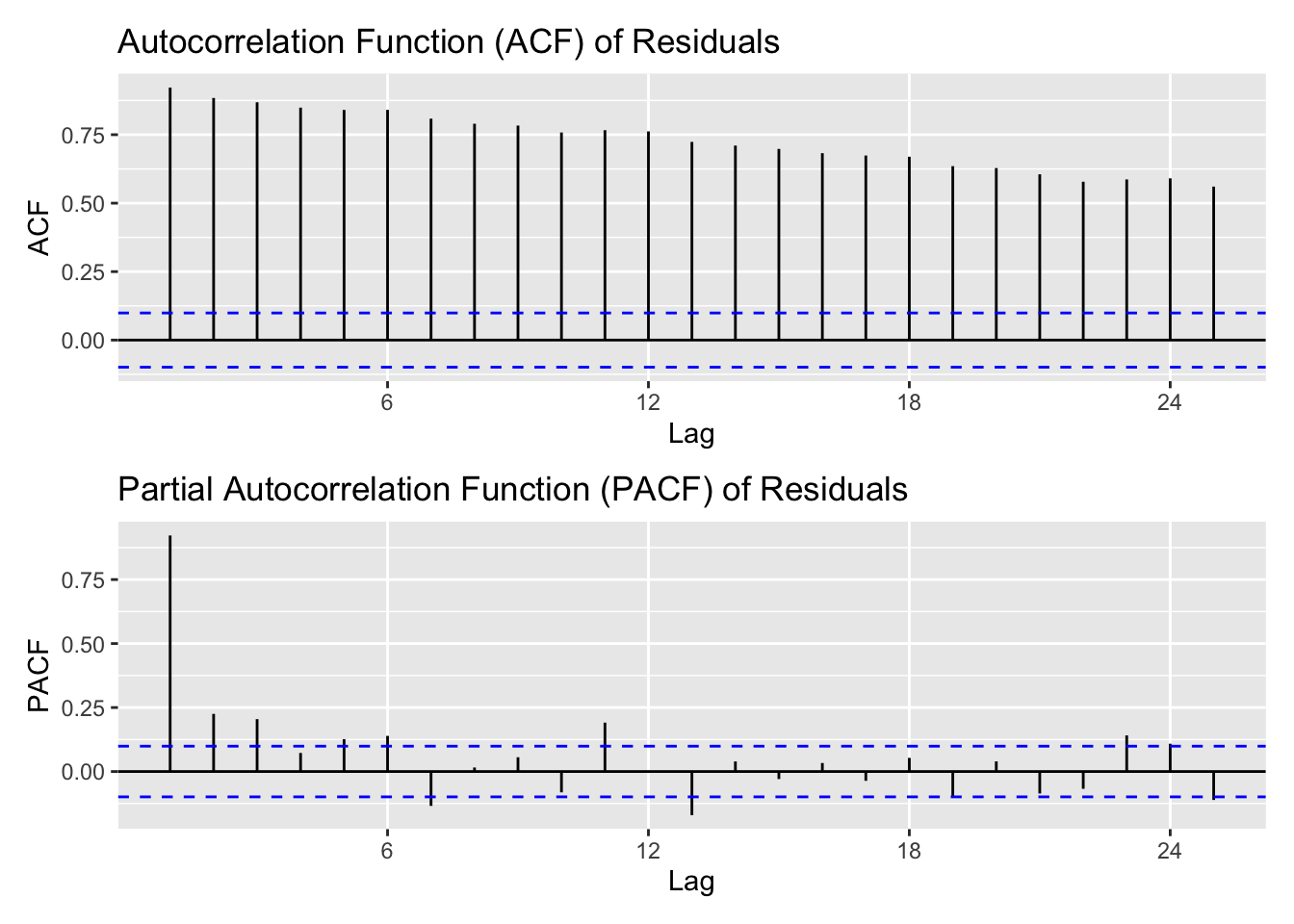
library(patchwork)res.fit1<-ts(residuals(m1),start =c(2000,12),frequency =12)acf1<-ggAcf(res.fit1) +ggtitle("Autocorrelation Function (ACF) of Residuals")pacf1<-ggPacf(res.fit1) +ggtitle("Partial Autocorrelation Function (PACF) of Residuals")acf1 / pacf1
Code
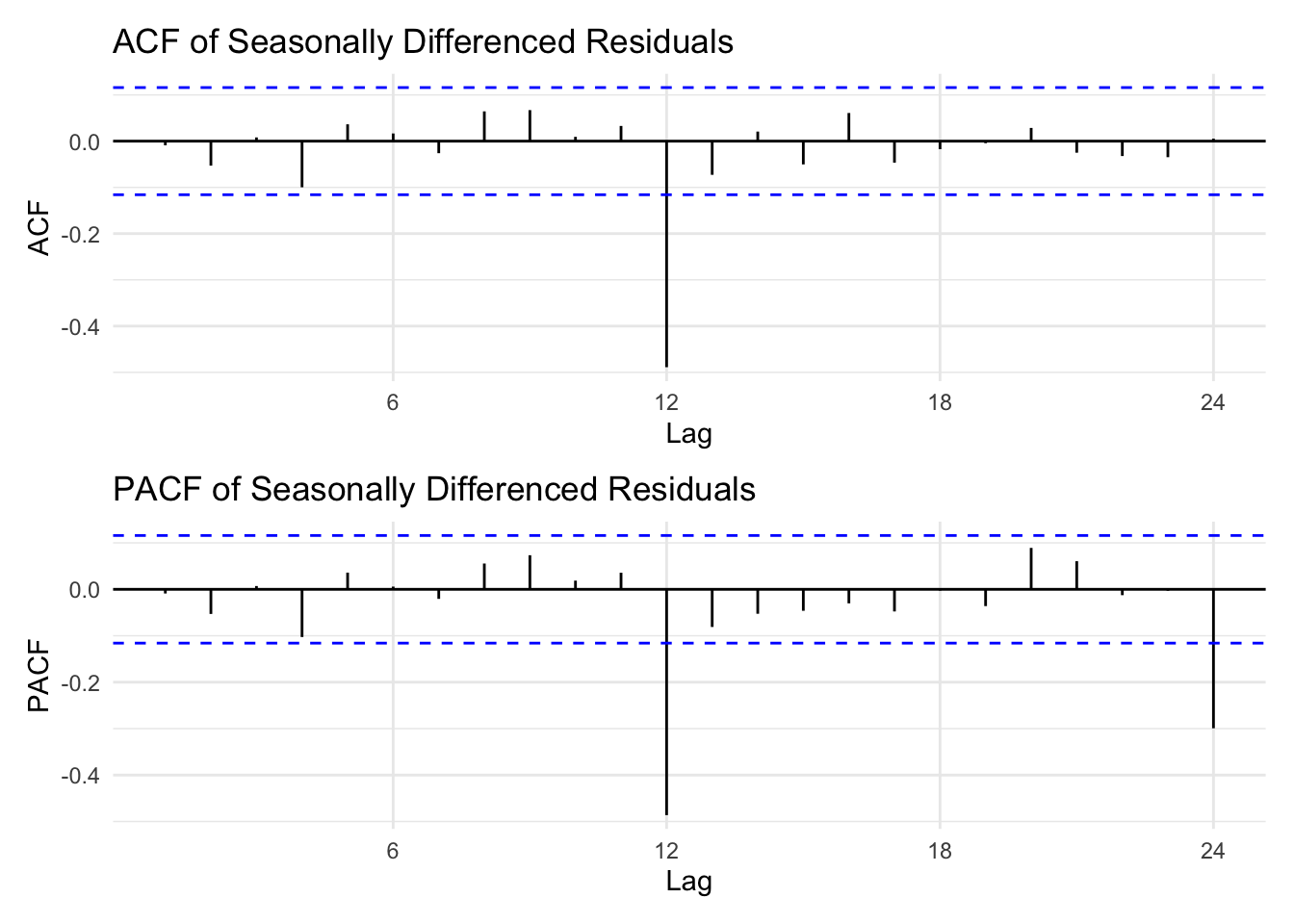
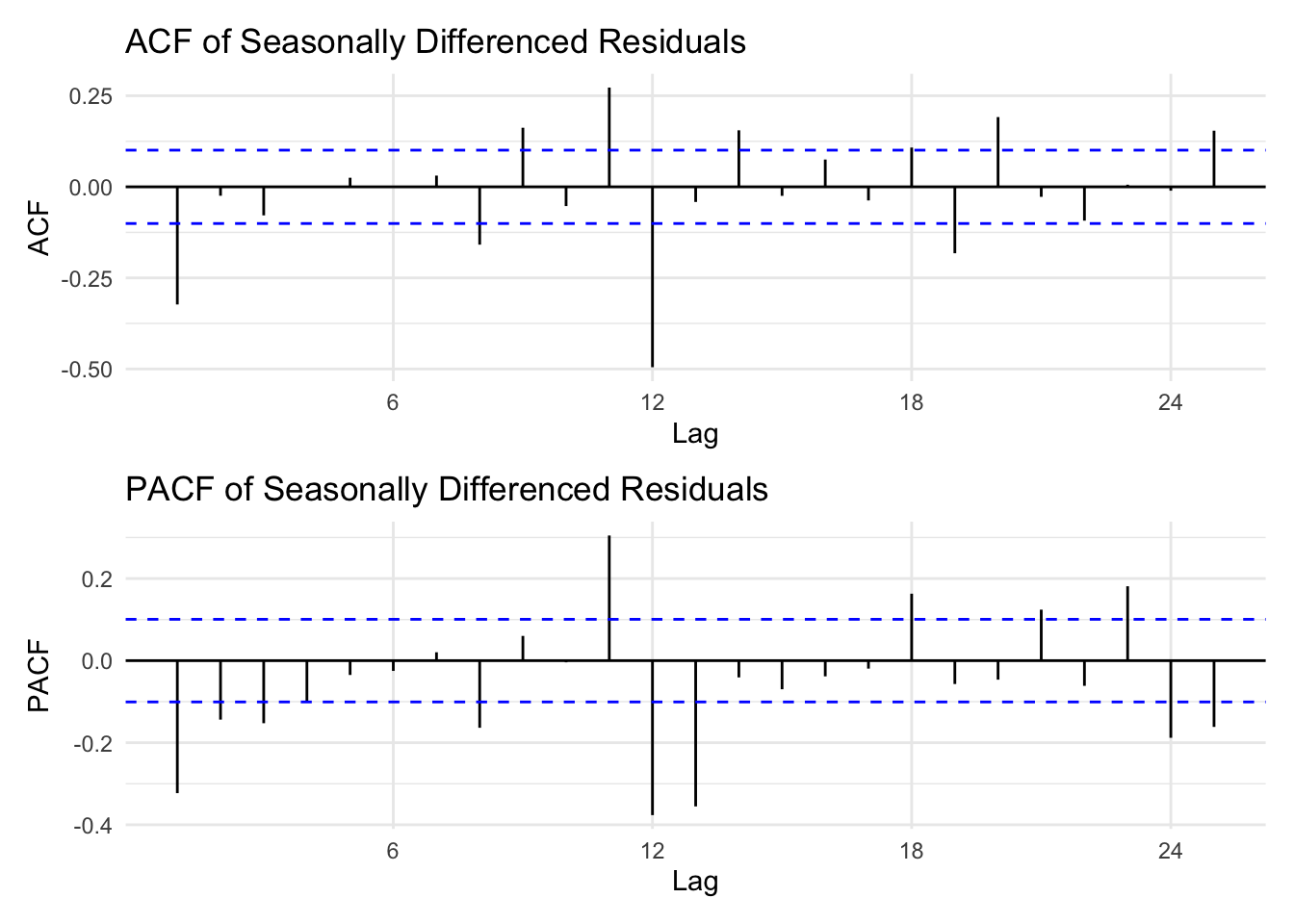
diff1<-diff(res.fit1)seasonal_diff1<-diff(diff1,lag =12)diff_p1 <-ggAcf(seasonal_diff1) +ggtitle("ACF of Seasonally Differenced Residuals") +theme_minimal()diff_p2 <-ggPacf(seasonal_diff1) +ggtitle("PACF of Seasonally Differenced Residuals") +theme_minimal()diff_p1 /diff_p2
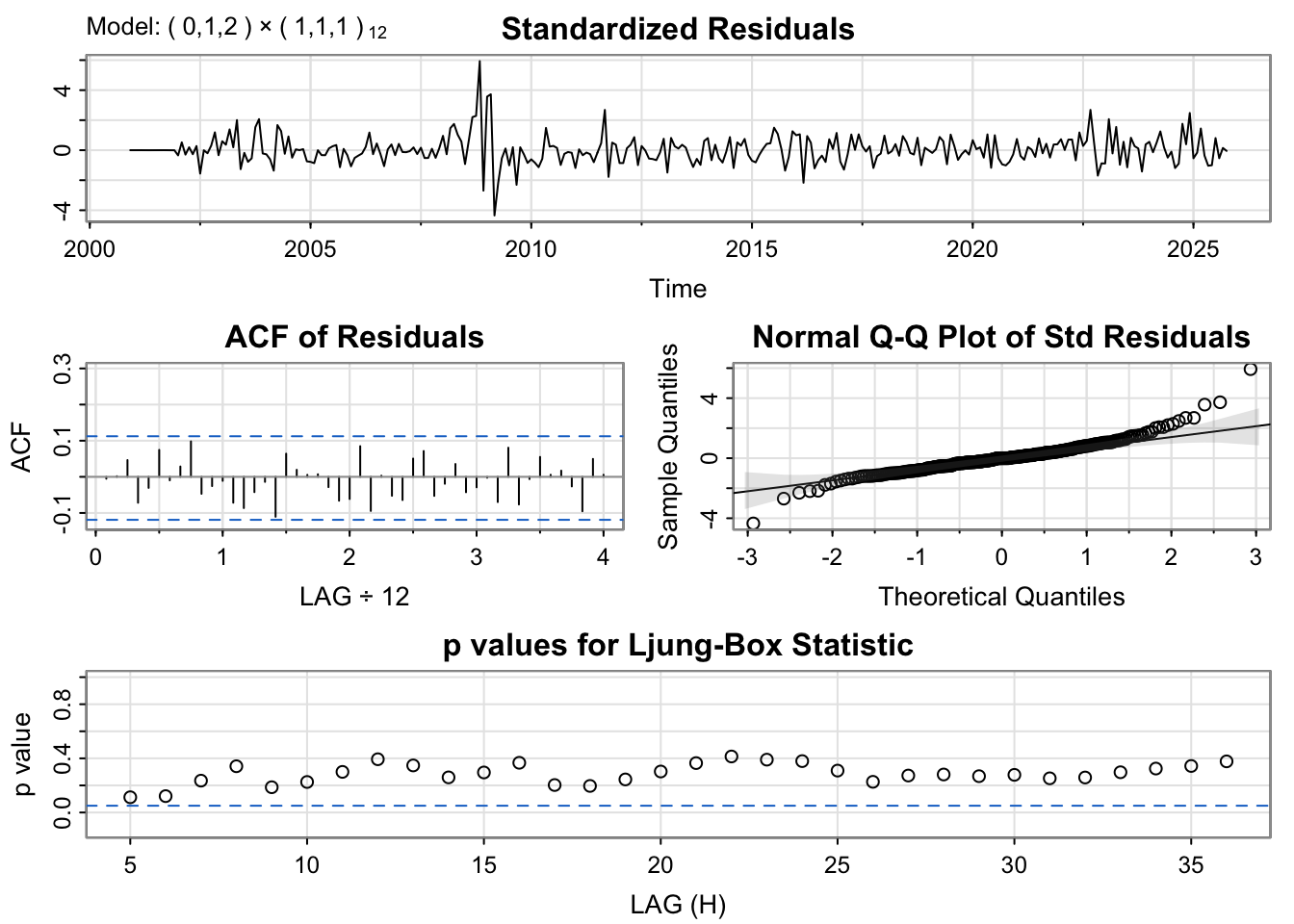
The ARIMA(0,1,2)(1,1,1)12 model produces residuals that behave much closer to white noise. The residual plot shows less obvious patterns or persistent fluctuations over time compared with the auto.arima model , indicating that both regular and seasonal differencing have successfully stabilized the series. The PACF of the residuals shows no significant spikes within the confidence bounds, suggesting that autocorrelation has been effectively removed. The Q–Q plot of standardized residuals aligns closely with the theoretical normal line, with only minor deviations at the tails. Furthermore, the Ljung–Box test p-values remain above the significance level across most lags, confirming the adequacy of the model fit. Overall, this model captures both the short-term and seasonal dynamics of the data well and provides a significant improvement over the auto.arima model.
RMSE for 12-Step Forecasts
Horizon1
RMSE_Model1
RMSE_Model2
1
75.2885
74.8425
2
75.5743
75.1145
3
75.3363
75.2164
4
74.7199
75.2525
5
74.5120
75.1724
6
74.3232
75.1111
7
74.2009
75.0476
8
74.2162
74.9261
9
74.2647
74.7324
10
74.3287
74.5284
11
74.4096
74.3075
12
74.3660
74.0836
Code
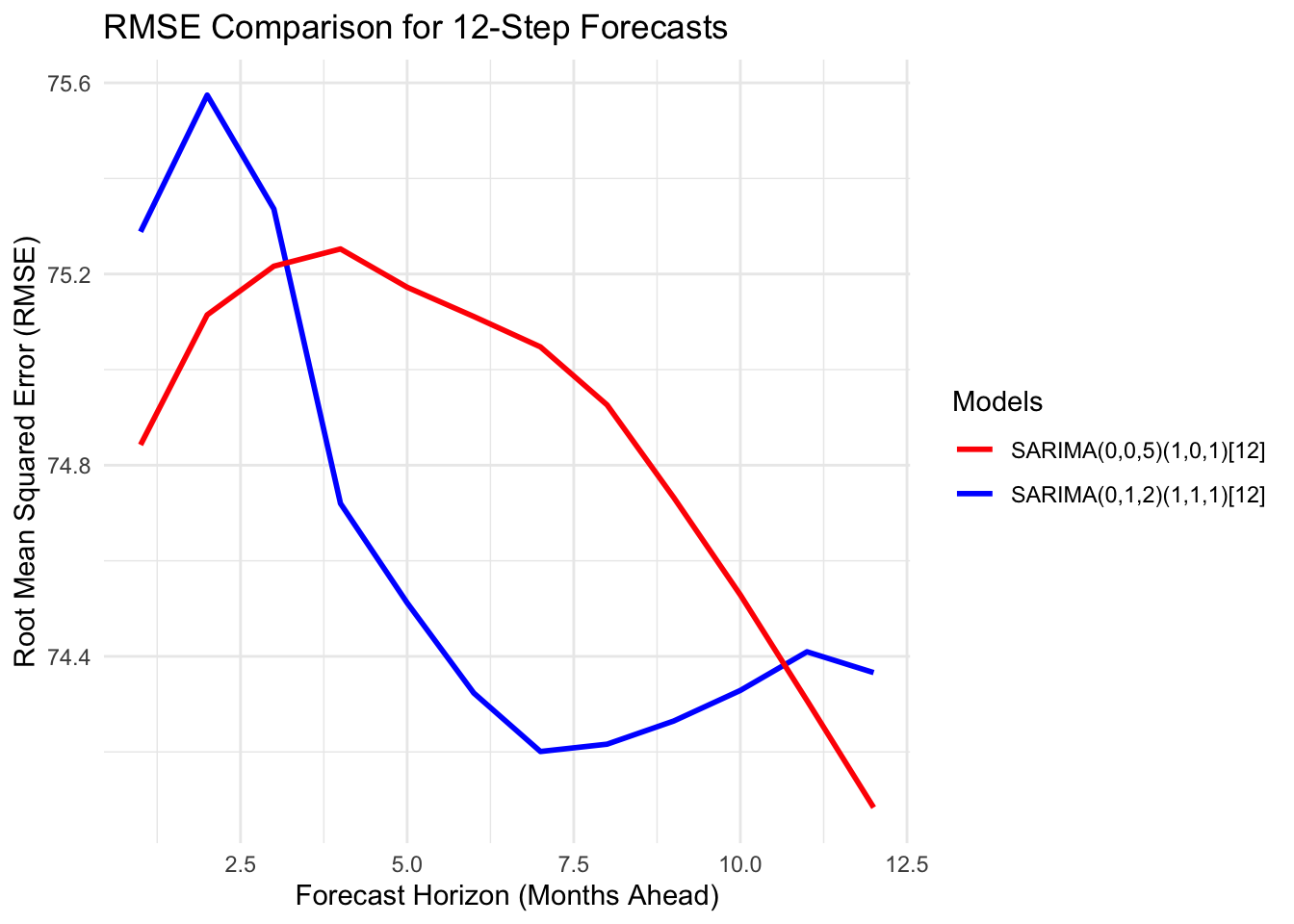
ggplot(rmse_table1, aes(x = Horizon1)) +geom_line(aes(y = RMSE_Model1, color ="SARIMA(0,1,2)(1,1,1)[12]"), size =1) +geom_line(aes(y = RMSE_Model2, color ="SARIMA(0,0,5)(1,0,1)[12]"), size =1) +labs(title ="RMSE Comparison for 12-Step Forecasts",x ="Forecast Horizon (Months Ahead)",y ="Root Mean Squared Error (RMSE)") +scale_color_manual(name ="Models", values =c("red", "blue")) +theme_minimal()
From the plots, the SARIMA(0,1,2)(1,1,1)[12] model demonstrates strong overall performance, capturing the main patterns and seasonal dynamics effectively across most of the time series. In contrast, the SARIMA(0,0,5)(1,0,1)[12] model performs slightly better in predicting values at the very beginning and end of the series, suggesting improved short-term and long-horizon accuracy. However, considering consistency and overall fit throughout the data, the SARIMA(0,1,2)(1,1,1)[12] model provides a more balanced and reliable performance. Therefore, this model is selected as the preferred choice.
fin_short_fit <-auto.arima(xreg1[, "US_KR_3Y"])fshort <-forecast(fin_short_fit, h =32) fin_long_fit <-auto.arima(xreg1[, "US_KR_10Y"])flong <-forecast(fin_long_fit, h =32)usd_fit <-auto.arima(xreg1[, "log_usd_index"])fusd <-forecast(usd_fit, h =32)sp_fit <-auto.arima(xreg1[, "log_sp500_close"])fsp <-forecast(sp_fit, h =32)fxreg1 <-cbind(US_KR_3Y = fshort$mean,US_KR_10Y = flong$mean,log_usd_index = fusd$mean,log_sp500_close = fsp$mean)
Code
library(plotly)fcast1 <-forecast(final_fit1, xreg = fxreg1, h =32)fcast_df1 <-data.frame(Date =as.Date(time(fcast1$mean)),Forecast =as.numeric(fcast1$mean),Lower80 =as.numeric(fcast1$lower[,1]),Upper80 =as.numeric(fcast1$upper[,1]),Lower95 =as.numeric(fcast1$lower[,2]),Upper95 =as.numeric(fcast1$upper[,2]))orig_df <-data.frame(Date =as.Date(time(y1)),Actual =as.numeric(y1))plot_ly() |>add_lines(data = orig_df,x =~Date, y =~Actual,name ="Actual") |>add_lines(data = fcast_df1,x =~Date, y =~Forecast,name ="Forecast") |>add_ribbons(data = fcast_df1,x =~Date,ymin =~Lower95,ymax =~Upper95,name ="95% CI",opacity =0.2,showlegend =FALSE) |>add_ribbons(data = fcast_df1,x =~Date,ymin =~Lower80,ymax =~Upper80,name ="80% CI",opacity =0.3,showlegend =FALSE) |>layout(title ="Forecast of KRW/USD exchange spot rate for next 36 month",xaxis =list(title ="Year"),yaxis =list(title ="KRW to one USD") )
The forecast demonstrates a good fit, closely following the pattern of previous values. Over time, the KRW is projected to appreciate gradually, showing only minor changes and limited fluctuations.
SARIMAX model : South korea exports(vs USA) ~ VIX + US manufacturing Index + KRW/USD spot rate
Series: y2
Regression with ARIMA(0,1,1)(0,0,2)[12] errors
Coefficients:
ma1 sma1 sma2 vix usm krw
-0.6613 0.3278 0.1766 -272.6394 97227.64 -317.6629
s.e. 0.0398 0.0544 0.0576 4246.8016 15051.92 341.1909
sigma^2 = 1.859e+11: log likelihood = -5625.82
AIC=11265.63 AICc=11265.93 BIC=11293.41
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 24238.72 427248.1 307163.3 -0.3682801 7.044885 0.5508381 0.0304862
Code
checkresiduals(fit_auto2)
Ljung-Box test
data: Residuals from Regression with ARIMA(0,1,1)(0,0,2)[12] errors
Q* = 71.466, df = 21, p-value = 2.042e-07
Model df: 3. Total lags used: 24
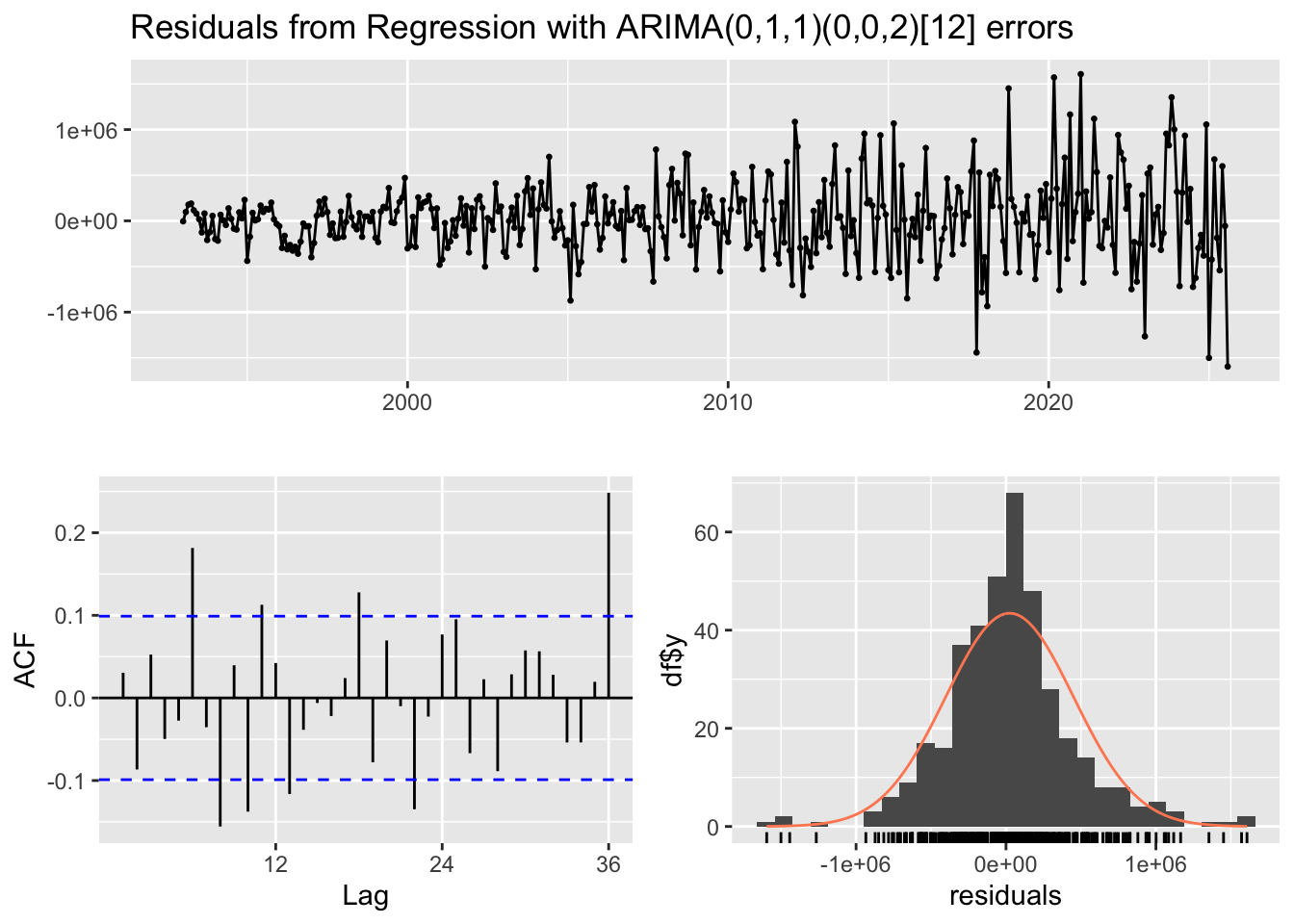
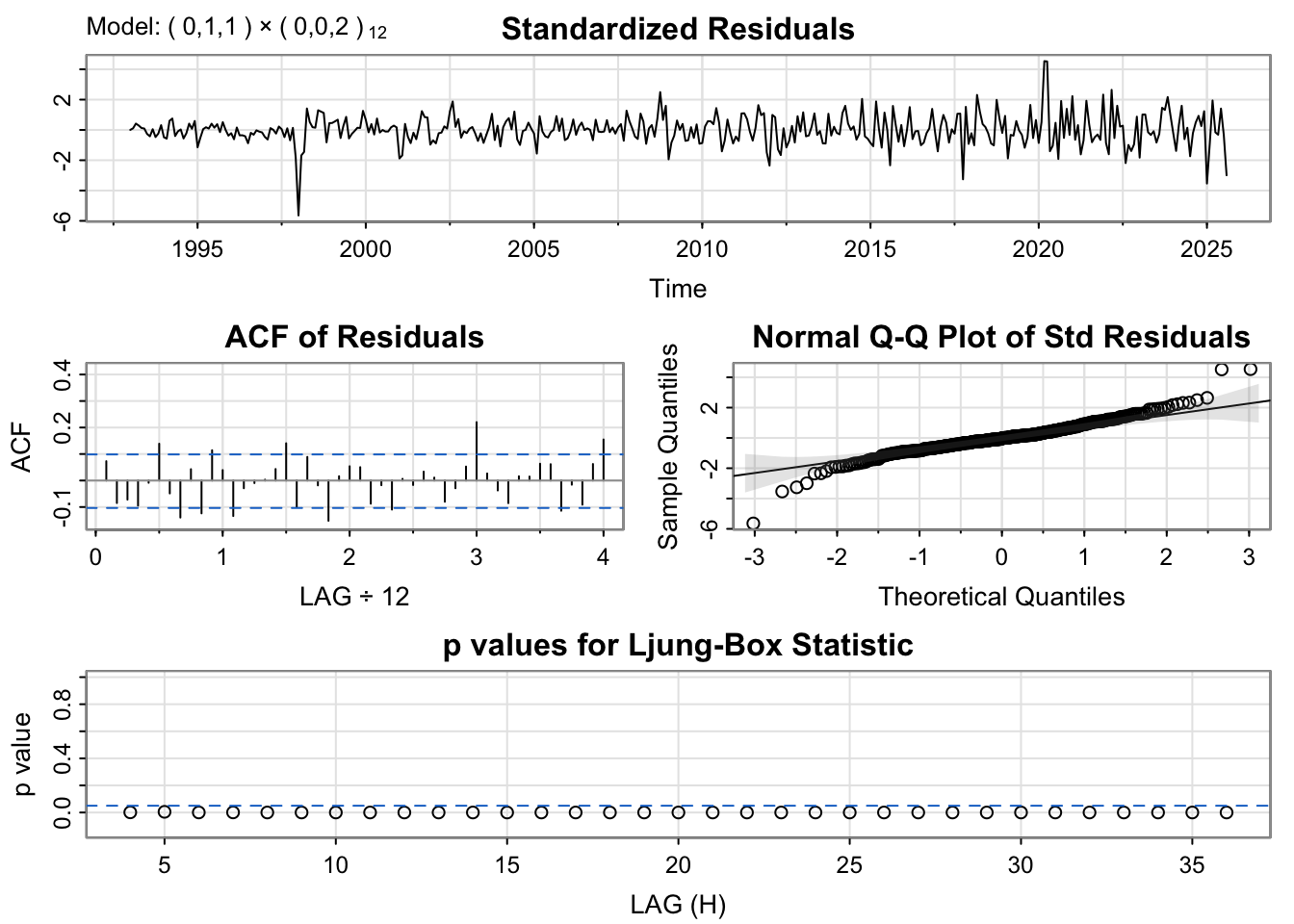
The ARIMA(0,1,1)(0,0,2)[12] model from auto.arima() yields residuals that fluctuate randomly around zero, though variability increases in recent years, indicating the fit is not perfect. The residual ACF shows only mild autocorrelation, with most lags within the 95% bounds, but a faint seasonal signal remains near lag 12. The residual histogram is approximately normal, with slight skewness driven by a few large observations.
Code
m2<-lm(exports~ usm+vix+krw, data = df4)summary(m2)
Call:
lm(formula = exports ~ usm + vix + krw, data = df4)
Residuals:
Min 1Q Median 3Q Max
-3846667 -1306009 -267557 1170558 4378304
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.166e+07 7.807e+05 -14.939 < 2e-16 ***
usm 1.405e+05 9.939e+03 14.138 < 2e-16 ***
vix -6.138e+04 1.243e+04 -4.937 1.18e-06 ***
krw 3.949e+03 6.564e+02 6.016 4.14e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1639000 on 388 degrees of freedom
Multiple R-squared: 0.5771, Adjusted R-squared: 0.5738
F-statistic: 176.5 on 3 and 388 DF, p-value: < 2.2e-16
Code
library(patchwork)res.fit2<-ts(residuals(m2),start =c(1993,1),frequency =12)acf2<-ggAcf(res.fit2) +ggtitle("Autocorrelation Function (ACF) of Residuals")pacf2<-ggPacf(res.fit2) +ggtitle("Partial Autocorrelation Function (PACF) of Residuals")acf2 / pacf2
Code
diff2<-diff(res.fit2)seasonal_diff2<-diff(diff2,lag =12)diff_p3 <-ggAcf(seasonal_diff2) +ggtitle("ACF of Seasonally Differenced Residuals") +theme_minimal()diff_p4 <-ggPacf(seasonal_diff2) +ggtitle("PACF of Seasonally Differenced Residuals") +theme_minimal()diff_p3 /diff_p4
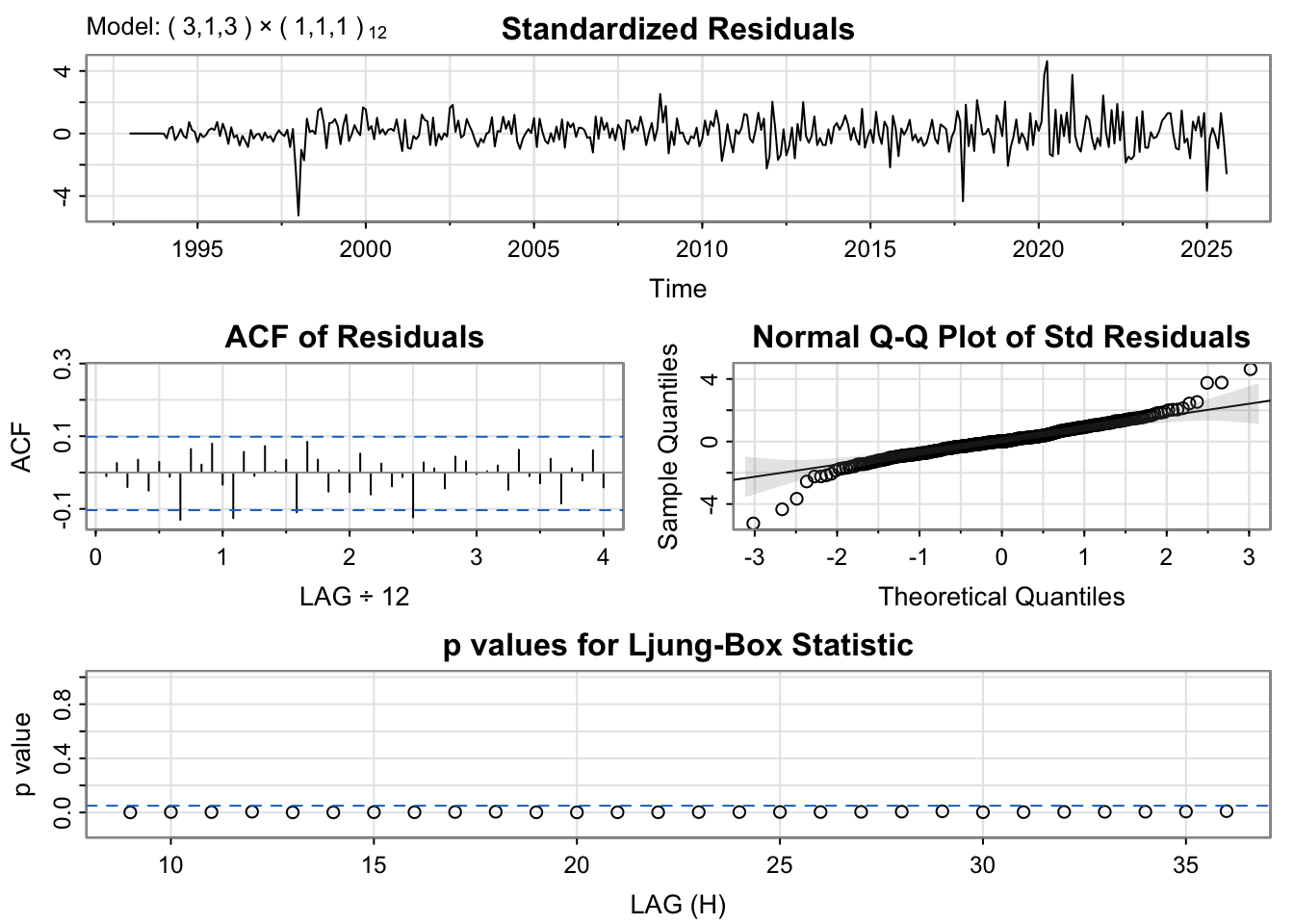
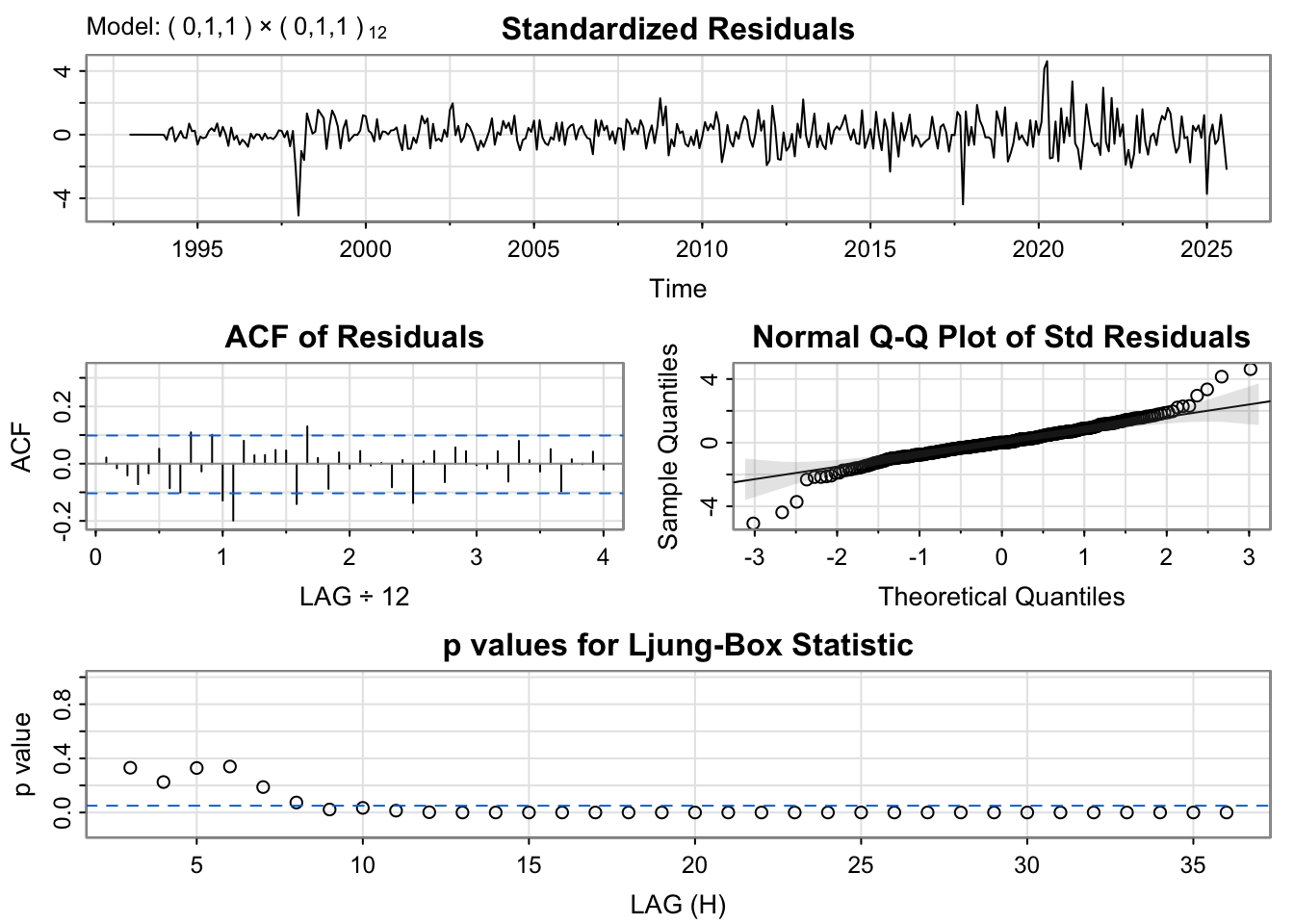
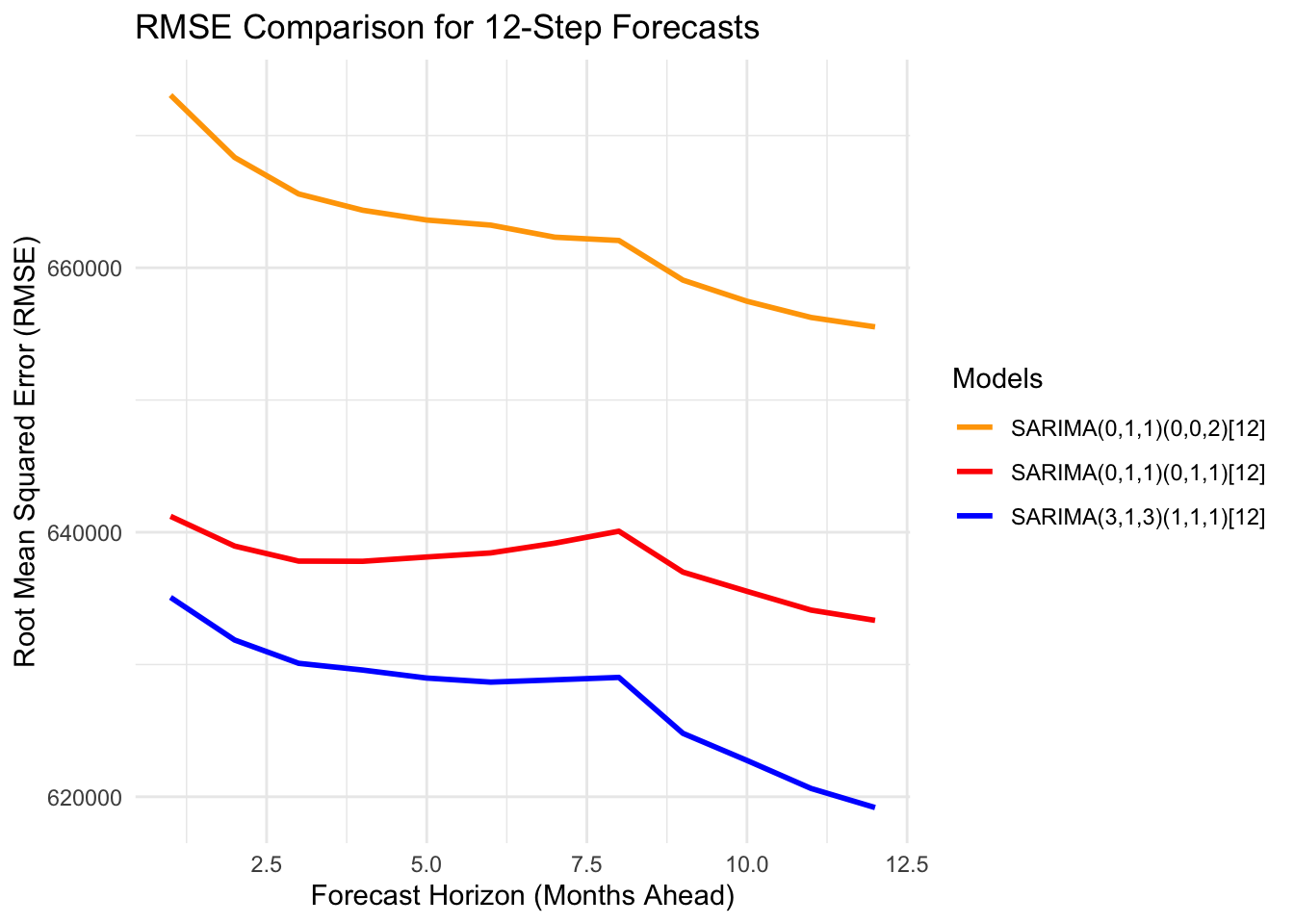
All three models display similar residual patterns, characterized by random fluctuations around zero with a few noticeable outlier spikes. The ACF plots of the residuals also show comparable behavior across models; however, the ARIMA(3,1,3)(1,1,1)[12] model performs slightly better, as its autocorrelations remain within the significance bounds across most lags. The normal Q–Q plots indicate that all models exhibit similar residual distributions, with deviations at the tails suggesting the presence of non-normality often observed in time series data. Although the Ljung–Box test results indicate that none of the models fully satisfy the white noise assumption—since most p-values fall below the significance threshold—the ARIMA(0,1,1)(0,1,1)[12] model appears to offer a marginally better fit compared to the others.
RMSE for 12-Step Forecasts
Horizon1
RMSE_Model1
RMSE_Model2
RMSE_Model3
1
635078.8
641208.0
673054.1
2
631856.4
638958.8
668345.2
3
630093.2
637819.6
665584.1
4
629582.7
637805.9
664351.6
5
628977.1
638130.8
663611.2
6
628669.7
638440.3
663223.7
7
628843.3
639176.5
662312.4
8
629025.6
640080.4
662063.7
9
624796.7
636988.8
659068.0
10
622747.3
635535.4
657468.8
11
620629.7
634116.4
656244.0
12
619185.3
633339.6
655531.3
Code
ggplot(rmse_table1, aes(x = Horizon1)) +geom_line(aes(y = RMSE_Model1, color ="SARIMA(3,1,3)(1,1,1)[12]"), size =1) +geom_line(aes(y = RMSE_Model2, color ="SARIMA(0,1,1)(0,1,1)[12]"), size =1) +geom_line(aes(y = RMSE_Model3, color ="SARIMA(0,1,1)(0,0,2)[12]"), size =1) +labs(title ="RMSE Comparison for 12-Step Forecasts",x ="Forecast Horizon (Months Ahead)",y ="Root Mean Squared Error (RMSE)") +scale_color_manual(name ="Models", values =c("orange","red", "blue")) +theme_minimal()
From the plot, SARIMA(3,1,3)(1,1,1)[12] performs better than other models, so SARIMA(3,1,3)(1,1,1)[12] model is best model.
usm_fit <-auto.arima(xreg2[, "usm"])fusm <-forecast(usm_fit, h =48) vix_fit <-auto.arima(xreg2[, "vix"])fvix <-forecast(vix_fit, h =48)krw_fit <-auto.arima(xreg2[, "krw"])fkrw <-forecast(krw_fit, h =48)fxreg2 <-cbind(vix = fvix$mean,usm = fusm$mean,krw = fkrw$mean)
Code
library(plotly)fcast2 <-forecast(final_fit2, xreg = fxreg2, h =48)orig_df <-data.frame(Date =as.Date(as.yearmon(time(y2))),Actual =as.numeric(y2))fcast_df2 <-data.frame(Date =as.Date(as.yearmon(time(fcast2$mean))),Forecast =as.numeric(fcast2$mean),Lower80 =as.numeric(fcast2$lower[,1]),Upper80 =as.numeric(fcast2$upper[,1]),Lower95 =as.numeric(fcast2$lower[,2]),Upper95 =as.numeric(fcast2$upper[,2]))plot_ly() |>add_lines(data = orig_df,x =~Date, y =~Actual,name ="Actual") |>add_lines(data = fcast_df2,x =~Date, y =~Forecast,name ="Forecast") |>add_ribbons(data = fcast_df2,x =~Date,ymin =~Lower95,ymax =~Upper95,name ="95% CI",opacity =0.2,showlegend =FALSE) |>add_ribbons(data = fcast_df2,x =~Date,ymin =~Lower80,ymax =~Upper80,name ="80% CI",opacity =0.3,showlegend =FALSE) |>layout(title ="Forecast of South korea export to US for next 48 month",xaxis =list(title ="Year"),yaxis =list(title ="thousand USD") )
The forecast demonstrates a strong fit, effectively capturing the pattern of historical values. Over the projection horizon, Korea’s exports in U.S. dollars are expected to exhibit an overall upward trend, although short-term monthly fluctuations are likely to continue.
Conclusion
The model-fitting process was satisfactory and produced reasonable forecasts across the four specifications. While the results are encouraging, no model is perfect, and additional refinement would further strengthen the analysis. Because macroeconomic and financial outcomes are shaped by many interacting forces, any empirical model will have limitations. Important drivers can be difficult to observe or may change over time, so the forecasts should be interpreted with appropriate caution.
Even so, the multivariate analysis yielded meaningful insights that align with established economic relationships. None of the models produced results that ran counter to typical behavior. Instead, the estimated effects were broadly consistent with how key variables usually interact—through risk sentiment, interest-rate differentials, exchange-rate channels, and demand conditions—making the forecast interpretations economically credible.
For the VAR linking U.S. and Korean equities (S&P 500, VIX, U.S. yield spread, and KOSPI), the forecast plot indicates firmer U.S. equity conditions and wider yield spreads alongside a softer KOSPI. This is consistent with the discount-rate and risk-transmission channels: tighter U.S. financial conditions and stronger dollar dynamics raise discount rates, elevate global risk premia, and tend to weigh on KRW-sensitive Korean equities.
For the VAR examining rate pass-through to Seoul housing (U.S. 10Y, Korea 10Y, and Seoul HPI), the forecast shows gradually easing long-term yields and a firmer housing index. The opposite co-movement is exactly what the affordability channel predicts: declines in global and domestic long rates filter into borrowing costs with lags, supporting housing demand and prices over time. For the SARIMAX model of USD/KRW (with rate differentials, U.S. equities/risk, and a broad dollar factor as exogenous drivers), the forecast suggests a mild KRW appreciation path with limited volatility. This reflects the background mechanism in which narrower rate differentials, improved risk sentiment, and a cooler broad dollar typically favor KRW strength, while the ARIMA component absorbs serial dependence in the exchange rate.
For the SARIMAX model of Korea’s exports to the United States (driven by U.S. demand, the exchange rate, and risk conditions), the forecast points to an upward trend tempered by month-to-month noise. Stronger U.S. manufacturing activity pulls Korean exports higher, while exchange-rate valuation and risk/financing conditions modulate near-term fluctuations—patterns commonly observed for dollar-invoicing exporters.
Looking ahead, the models can be enhanced with deeper diagnostics, and the addition of relevant external variables such as global demand proxies beyond the U.S., commodity prices, and credit conditions. Taken together, the four models provide a coherent basis for narrative forecasting while highlighting clear avenues for continued improvement.
Reference
1.
Kim, S. Do s&p 500 and KOSPI move together? A functional regression approach. KDI Economic Policy Review (2010).
2.
Lee, C. The time-varying effect of interest rates on housing prices. Land (2022).
3.
Min, C.-H. Time-varying analysis of housing prices in korea and the u.s. International Journal of Labor Economics (2024).
4.
Yoon, D. R. What determines the exchange rate of the korean won? (2019).
5.
Masujima, M. The shifting drivers of exchange rates. (2018).
6.
Son, M. et al. Dominant currency pricing: Evidence from korean exports. (2023).